基于Kernel 4.4源码
kernel/include/linux/sched.h
kernel/include/linux/kthread.h
kernel/arch/arm/include/asm/thread_info.h
kernel/kernel/fork.c
kernel/kernel/exit.c
kernel/kernel/sched/core.c
一. 概述
Linux创建进程采用fork()和exec()
- fork: 采用复制当前进程的方式来创建子进程,此时子进程与父进程的区别仅在于pid, ppid以及资源统计量(比如挂起的信号)
- exec:读取可执行文件并载入地址空间执行;一般称之为exec函数族,有一系列exec开头的函数,比如execl, execve等
fork过程复制资源包括代码段,数据段,堆,栈。fork调用者所在进程便是父进程,新创建的进程便是子进程;在fork调用结束,从内核返回两次,一次继续执行父进程,一次进入执行子进程。
1.1 进程创建
- Linux进程创建: 通过fork()系统调用创建进程
- Linux用户级线程创建:通过pthread库中的pthread_create()创建线程
- Linux内核线程创建: 通过kthread_create()
Linux线程,也并非”轻量级进程”,在Linux看来线程是一种进程间共享资源的方式,线程可看做是跟其他进程共享资源的进程。
fork, vfork, clone根据不同参数调用do_fork
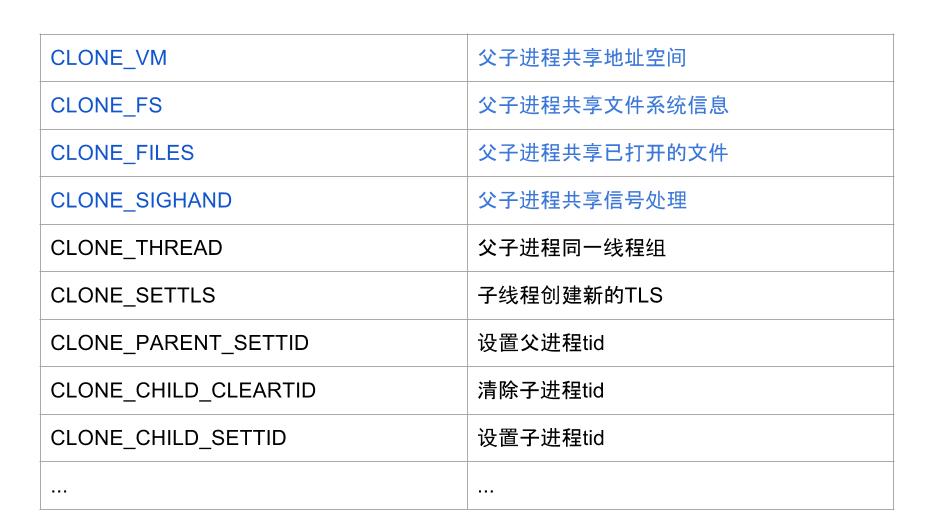
- pthread_create: flags参数为 CLONE_VM, CLONE_FS, CLONE_FILES, CLONE_SIGHAND
- fork: flags参数为 SIGCHLD
- vfork: flags参数为 CLONE_VFORK, CLONE_VM, SIGCHLD
1.2 fork流程图
进程/线程创建的方法fork(),pthread_create(), 万物归一,最终在linux都是调用do_fork方法。 当然还有vfork其实也是一样的, 通过系统调用到sys_vfork,然后再调用do_fork方法,该方法 现在很少使用,所以下图省略该方法。
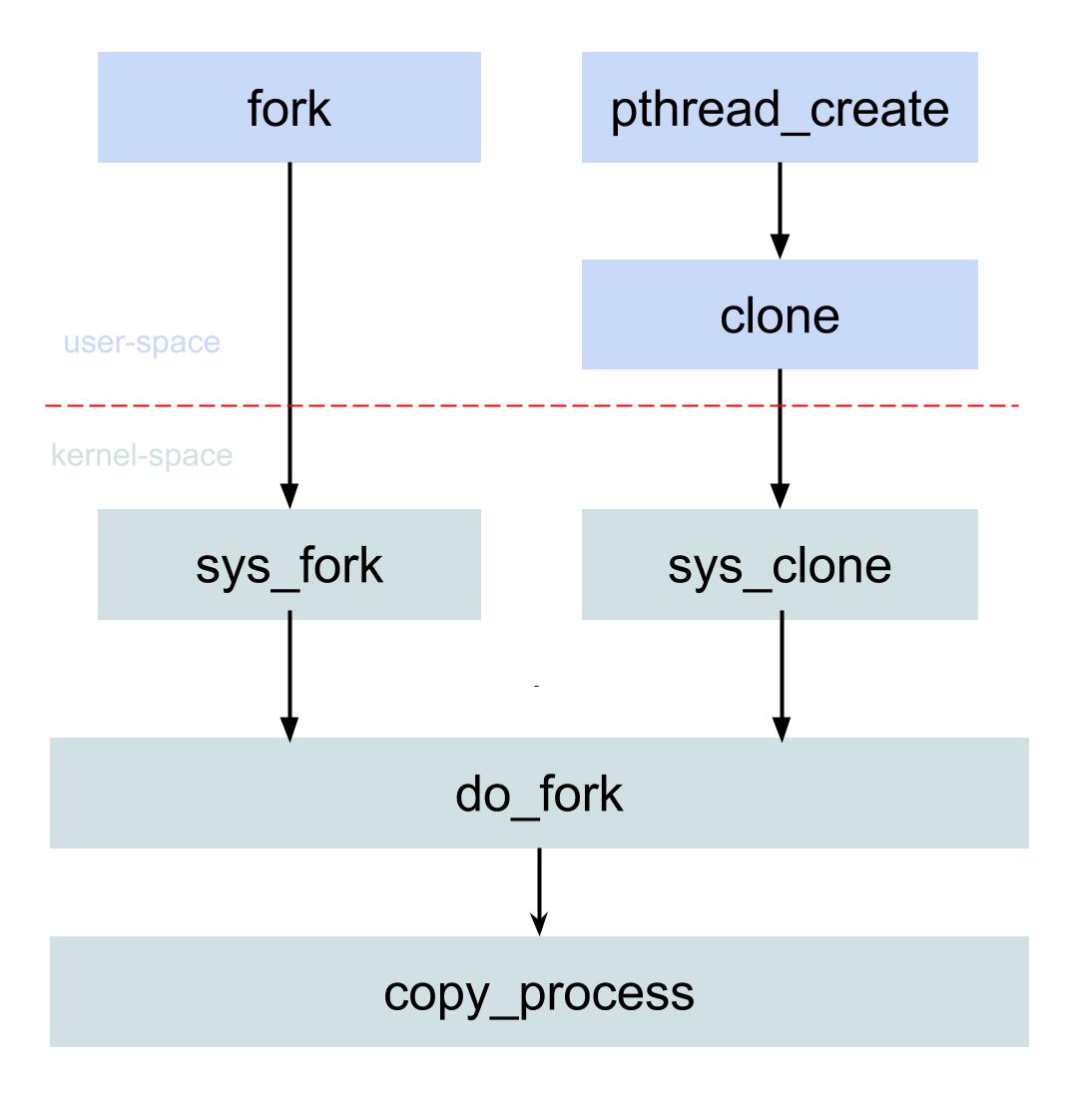
fork执行流程:
- 用户空间调用fork()方法;
- 经过syscall陷入内核空间, 内核根据系统调用号找到相应的sys_fork系统调用;
- sys_fork()过程会在调用do_fork(), 该方法参数有一个flags很重要, 代表的是父子进程之间需要共享的资源; 对于进程创建flags=SIGCHLD, 即当子进程退出时向父进程发送SIGCHLD信号;
- do_fork(),会进行一些check过程,之后便是进入核心方法copy_process.
1.3 flags参数
进程与线程最大的区别在于资源是否共享,线程间共享的资源主要包括内存地址空间,文件系统,已打开文件,信号等信息, 如下图蓝色部分的flags便是线程创建过程所必需的参数。
fork采用Copy on Write机制,父子进程共用同一块内存,只有当父进程或者子进程执行写操作时会拷贝一份新内存。 另外,创建进程也是有可能失败,比如进程个数达到系统上限(32768)或者系统可用内存不足。
接下来进一步介绍fork过程。
二. fork源码分析
linux程序执行fork方法,通过中断(syscall)陷入内核,执行系统提供的相应系统调用来完成进程创建过程。
2.1 fork
[-> kernel/fork.c]
2.1.1 fork
//fork系统调用
SYSCALL_DEFINE0(fork)
{
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
}
2.1.2 vfork
//vfork系统调用
SYSCALL_DEFINE0(vfork)
{
return _do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL, 0);
}
2.1.3 clone
//clone系统调用
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
unsigned long, tls,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#endif
{
return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls);
}
#endif
可见,fork,vfork,clone最终都会调用do_fork方法,仅仅是flags不同。
2.2 do_fork
[-> kernel/fork.c]
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
return _do_fork(clone_flags, stack_start, stack_size,
parent_tidptr, child_tidptr, 0);
}
参数说明:
- clone_flags:clone方法传递过程的flags,标记子进程从父进程中需要继承的资源清单
- stack_start: 子进程用户态的堆栈地址,fork()过程该值为0, clone()过程赋予有效值
- stack_size:不必要的参数,默认设置为0
- parent_tidptr:用户态下父进程的tid地址
- child_tidptr:用户态下子进程的tid地址
- tls:
2.3 _do_fork
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
...
//复制进程描述符【见小节2.4】
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
//获取新创建的子进程的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) { //仅用于vfork过程,初始化
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p); //唤醒子进程,分配CPU时间片
if (unlikely(trace)) //告知ptracer,子进程已创建完成,并且已启动
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) { //仅用于vfork过程,等待子进程
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
该方法过程说明:
- 执行copy_process,复制进程描述符,pid分配也是这个过程完成
- 当为vfork,则执行相应的初始化过程
- 执行wake_up_new_task,唤醒子进程,分配CPU时间片
- 当为vfork,则父进程等待子进程执行exec函数来替换地址空间
2.4 copy_process
[-> kernel/fork.c]
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls)
{
int retval;
struct task_struct *p;
void *cgrp_ss_priv[CGROUP_CANFORK_COUNT] = {};
...
retval = security_task_create(clone_flags);
...
//【见小节2.4.1】
p = dup_task_struct(current);
...
rt_mutex_init_task(p); //初始化mutex
//检查进程数是否超过上限
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags);
...
//检查nr_threads是否超过max_threads
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
delayacct_tsk_init(p);
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER);
p->flags |= PF_FORKNOEXEC;
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock); //初始化自旋锁
init_sigpending(&p->pending); //初始化挂起信号
p->utime = p->stime = p->gtime = 0;
p->utimescaled = p->stimescaled = 0;
prev_cputime_init(&p->prev_cputime);
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
p->start_time = ktime_get_ns(); //初始化进程启动时间
p->real_start_time = ktime_get_boot_ns();
p->io_context = NULL;
p->audit_context = NULL;
cgroup_fork(p);
p->pagefault_disabled = 0;
//执行调度器相关设置,将该task分配给一某个CPU 【见小节2.4.2】
retval = sched_fork(clone_flags, p);
retval = perf_event_init_task(p);
retval = audit_alloc(p);
//拷贝进程的所有信息[见小节3.1]
shm_init_task(p);
retval = copy_semundo(clone_flags, p);
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);
retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls);
if (pid != &init_struct_pid) {
//分配pid[见小节2.4.3]
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
...
}
...
p->pid = pid_nr(pid); //设置pid
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
p->nr_dirtied = 0;
p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10);
p->dirty_paused_when = 0;
p->pdeath_signal = 0;
INIT_LIST_HEAD(&p->thread_group);
p->task_works = NULL;
threadgroup_change_begin(current);
...
//CLONE_PARENT再利用旧的父进程
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
copy_seccomp(p);
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_cancel_cgroup;
}
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
atomic_inc(¤t->signal->sigcnt);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++; //线程个数+1
}
total_forks++; //进程forks次数加1
...
return p;
...
fork_out:
return ERR_PTR(retval);
}
主要功能:
- 执行dup_task_struct(),拷贝当前进程task_struct
- 检查进程数是否超过系统所允许的上限(默认32678)
- 执行sched_fork(),设置调度器相关信息,设置task进程状态为TASK_RUNNING,并分配CPU资源
- 执行copy_xxx(),拷贝进程的files, fs, mm, io, sighand, signal等信息
- 执行copy_thread_tls(), 拷贝子进程的内核栈信息
- 执行alloc_pid(),为新进程分配新pid
2.4.1 dup_task_struct
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tsk_fork_get_node(orig);
int err;
//分配task_struct节点
tsk = alloc_task_struct_node(node);
//分配thread_info节点
ti = alloc_thread_info_node(tsk, node);
err = arch_dup_task_struct(tsk, orig);
//将thread_info赋值给当前新创建的task
tsk->stack = ti;
setup_thread_stack(tsk, orig);
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
set_task_stack_end_magic(tsk);
...
account_kernel_stack(ti, 1);
return tsk;
}
该方法主要功能是创建task_struct和thread_info结构体。执行完该方法,子进程唯一不同是tsk->stack。
2.4.2 sched_fork
[-> sched/core.c]
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
int cpu = get_cpu();
__sched_fork(clone_flags, p);
//标记进程为Running状态,用于保证实际上并没有运行,
// 信号或许其他外部事件都无法唤醒该进程,同时把它插入运行队列
p->state = TASK_RUNNING;
//确保不会将提升的优先级传递到子进程
p->prio = current->normal_prio;
...
//为进程p分配相应cpu
set_task_cpu(p, cpu);
...
put_cpu();
return 0;
}
2.4.3 alloc_pid
[-> kernel/kernel/pid.c]
struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
...
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp); //分配pid
...
pid->numbers[i].nr = nr; //nr保存到pid结构体
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
...
return pid;
}
通过alloc_pidmap()方法来完成pid的分配工作,具体分配算法见下一篇文章Linux进程pid分配法
接下来的重头大戏是关于fs,mm等结构体的复制,见下面的过程。
三. 拷贝过程
3.1 copy_semundo
[-> kernel/ipc/sem.c]
int copy_semundo(unsigned long clone_flags, struct task_struct *tsk)
{
struct sem_undo_list *undo_list;
int error;
if (clone_flags & CLONE_SYSVSEM) {
error = get_undo_list(&undo_list);
if (error)
return error;
atomic_inc(&undo_list->refcnt);
tsk->sysvsem.undo_list = undo_list;
} else
tsk->sysvsem.undo_list = NULL;
return 0;
}
当设置CLONE_SYSVSEM,则父子进程间共享SEM_UNDO状态
3.2 copy_files
[-> fork.c]
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
int error = 0;
//如果是后台进程可能没有files
oldf = current->files;
if (!oldf)
goto out;
//设置CLONE_FILES,则只增加文件引用计数
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
//创建新的files_struct,并拷贝内容【见小节3.2.1】
newf = dup_fd(oldf, &error);
if (!newf)
goto out;
tsk->files = newf; //新创建的files_struct赋值给新进程
error = 0;
out:
return error;
}
- 当父进程没有打开文件,则不需要执行文件拷贝
- 当设置CLONE_FILES,则只增加文件引用计数,不创建新的files_struct
- 以上都不满足,则创建新的files_struct,并拷贝内容
3.2.1 dup_fd
[-> kernel/fs/file.c]
struct files_struct *dup_fd(struct files_struct *oldf, int *errorp)
{
//结构体成员【见小节3.2.2】
struct files_struct *newf;
struct file **old_fds, **new_fds;
int open_files, i;
struct fdtable *old_fdt, *new_fdt;
//创建新files_struct结构体
newf = kmem_cache_alloc(files_cachep, GFP_KERNEL);
...
atomic_set(&newf->count, 1);
spin_lock_init(&newf->file_lock);
newf->resize_in_progress = false;
init_waitqueue_head(&newf->resize_wait);
newf->next_fd = 0;
//初始化新的fdtable
new_fdt = &newf->fdtab;
//NR_OPEN_DEFAULT等于BITS_PER_LONG,默认大小为32
new_fdt->max_fds = NR_OPEN_DEFAULT;
new_fdt->close_on_exec = newf->close_on_exec_init;
new_fdt->open_fds = newf->open_fds_init;
new_fdt->full_fds_bits = newf->full_fds_bits_init;
new_fdt->fd = &newf->fd_array[0];
spin_lock(&oldf->file_lock); //获取自旋锁
//获取oldf->fdt
old_fdt = files_fdtable(oldf);
//获取父进程(old_fdt)所打开的文件个数 【见小节3.2.3】
open_files = count_open_files(old_fdt);
//当父进程打开的文件个数超过32个,则需要分配更大的fd数组/集合
while (unlikely(open_files > new_fdt->max_fds)) {
spin_unlock(&oldf->file_lock); //释放自旋锁
if (new_fdt != &newf->fdtab)
__free_fdtable(new_fdt);
//分配更多的fdtable, 大小至少1KB且满足2的指数次方【见小节3.2.4】
new_fdt = alloc_fdtable(open_files - 1);
...
//重新获取oldf锁,检查oldf最新打开的文件个数,再次检查是否小于max_fds.
spin_lock(&oldf->file_lock);
old_fdt = files_fdtable(oldf);
open_files = count_open_files(old_fdt);
}
//拷贝父进程的fdtable信息【见小节3.2.5】
copy_fd_bitmaps(new_fdt, old_fdt, open_files);
old_fds = old_fdt->fd;
new_fds = new_fdt->fd;
for (i = open_files; i != 0; i--) {
struct file *f = *old_fds++;
if (f) {
get_file(f);
} else {
//fd已申明在fd数组,但是还没有文件open操作刚进行到一半,那么对于新进程不可用,则需要清除
__clear_open_fd(open_files - i, new_fdt);
}
//先把内存写好,再把指针f赋值给new_fds, rcu机制保证数据一致性
rcu_assign_pointer(*new_fds++, f);
}
spin_unlock(&oldf->file_lock);
//剩下的内存空间数据清零
memset(new_fds, 0, (new_fdt->max_fds - open_files) * sizeof(struct file *));
//将new_fdt赋值给newf->fdt
rcu_assign_pointer(newf->fdt, new_fdt);
return newf;
out_release:
kmem_cache_free(files_cachep, newf);
out:
return NULL;
}
该方法主要作用是创建和拷贝fdtable内容,然后赋值给新的file_struct的成员指针fdt;
关于RCU的几个方法说明:
- rcu_read_lock:用于保护读者的RCU临界区,禁止抢占,不允许上下文切换;
- rcu_read_unlock:解除保护,恢复抢占
- rcu_assign_pointer:用于写者更新被RCU保护的指针
- rcu_dereference:用于读者获取被RCU保护的指针
- synchronize_rcu:等待之前所有的读取全部完成
要判断是不是被rcu_read_lock,可以观察是否发生了上下文切换(Context switch);
3.2.2 files_struct结构体
[-> kernel/include/linux/fdtable.h]
struct files_struct {
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt; //记录fdtable指针
struct fdtable fdtab; //记录fdtable
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
#define NR_OPEN_DEFAULT BITS_PER_LONG
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd; //当前fd数组
unsigned long *close_on_exec;
unsigned long *open_fds; //打开的文件描述符
unsigned long *full_fds_bits;
struct rcu_head rcu;
};
3.2.3 count_open_files
[-> kernel/fs/file.c]
static int count_open_files(struct fdtable *fdt)
{
int size = fdt->max_fds; //文件描述符的最大上限
int i;
//查询最后打开的fd, 其中BITS_PER_LONG=32
for (i = size / BITS_PER_LONG; i > 0; ) {
if (fdt->open_fds[--i])
break;
}
i = (i + 1) * BITS_PER_LONG;
return i;
}
3.2.4 alloc_fdtable
[-> kernel/fs/file.c]
static struct fdtable * alloc_fdtable(unsigned int nr)
{
struct fdtable *fdt;
void *data;
//保证fd数组大小至少1KB,且fd个数是2的指数次方
nr /= (1024 / sizeof(struct file *));
nr = roundup_pow_of_two(nr + 1);
nr *= (1024 / sizeof(struct file *));
if (unlikely(nr > sysctl_nr_open))
nr = ((sysctl_nr_open - 1) | (BITS_PER_LONG - 1)) + 1;
//分配内存
fdt = kmalloc(sizeof(struct fdtable), GFP_KERNEL);
fdt->max_fds = nr;
data = alloc_fdmem(nr * sizeof(struct file *));
fdt->fd = data;
data = alloc_fdmem(max_t(size_t,
2 * nr / BITS_PER_BYTE + BITBIT_SIZE(nr), L1_CACHE_BYTES));
fdt->open_fds = data;
data += nr / BITS_PER_BYTE;
fdt->close_on_exec = data;
data += nr / BITS_PER_BYTE;
fdt->full_fds_bits = data;
return fdt;
out_arr:
kvfree(fdt->fd);
out_fdt:
kfree(fdt);
out:
return NULL;
}
更新fdt的max_fds,fd,open_fds,close_on_exec,full_fds_bits数据。
3.2.5 copy_fd_bitmaps
[-> file.c]
static void copy_fd_bitmaps(struct fdtable *nfdt, struct fdtable *ofdt,
unsigned int count)
{
unsigned int cpy, set;
cpy = count / BITS_PER_BYTE;
set = (nfdt->max_fds - count) / BITS_PER_BYTE;
memcpy(nfdt->open_fds, ofdt->open_fds, cpy);
memset((char *)nfdt->open_fds + cpy, 0, set);
memcpy(nfdt->close_on_exec, ofdt->close_on_exec, cpy);
memset((char *)nfdt->close_on_exec + cpy, 0, set);
cpy = BITBIT_SIZE(count);
set = BITBIT_SIZE(nfdt->max_fds) - cpy;
memcpy(nfdt->full_fds_bits, ofdt->full_fds_bits, cpy);
memset((char *)nfdt->full_fds_bits + cpy, 0, set);
}
该方法的功能:将ofdt的成员变量open_fds和close_on_exec以及full_fds_bits数据拷贝到nfdt,没有数据的地方用0填充。
3.3 copy_fs
[-> fork.c]
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{
//结构体【见小节3.3.1】
struct fs_struct *fs = current->fs;
if (clone_flags & CLONE_FS) {
spin_lock(&fs->lock); //获取自旋锁
if (fs->in_exec) {
spin_unlock(&fs->lock);
return -EAGAIN;
}
fs->users++; //用户数加1
spin_unlock(&fs->lock);
return 0;
}
//拷贝fs_struct【见小节3.3.2】
tsk->fs = copy_fs_struct(fs);
if (!tsk->fs)
return -ENOMEM;
return 0;
}
该方法的功能:
- 当设置CLONE_FS,且没有执行exec, 则设置用户数加1
- 当未设置CLONE_FS,则拷贝fs_struct结构体
3.3.1 fs_struct
[-> kernel/include/linux/fs_struct.h]
struct fs_struct {
int users;
spinlock_t lock;
seqcount_t seq;
int umask;
int in_exec;
struct path root, pwd;
};
3.3.2 copy_fs_struct
[-> kernel/fs/fs_struct.c]
struct fs_struct *copy_fs_struct(struct fs_struct *old)
{
struct fs_struct *fs = kmem_cache_alloc(fs_cachep, GFP_KERNEL);
if (fs) {
fs->users = 1;
fs->in_exec = 0;
spin_lock_init(&fs->lock);
seqcount_init(&fs->seq);
fs->umask = old->umask;
spin_lock(&old->lock);
fs->root = old->root;
path_get(&fs->root);
fs->pwd = old->pwd;
path_get(&fs->pwd);
spin_unlock(&old->lock);
}
return fs;
}
3.4 copy_sighand
[-> fork.c]
static int copy_sighand(unsigned long clone_flags, struct task_struct *tsk)
{
//【见小节3.4.1】
struct sighand_struct *sig;
if (clone_flags & CLONE_SIGHAND) {
atomic_inc(¤t->sighand->count);
return 0;
}
sig = kmem_cache_alloc(sighand_cachep, GFP_KERNEL);
rcu_assign_pointer(tsk->sighand, sig);
if (!sig)
return -ENOMEM;
atomic_set(&sig->count, 1);
memcpy(sig->action, current->sighand->action, sizeof(sig->action));
return 0;
}
该方法的功能:
- 当设置CLONE_SIGHAND, 则增加sighand->count计数
- 当未设置CLONE_SIGHAND,则创建新的sighand_struct结构体
3.4.1 sighand_struct结构体
[-> kernel/include/linux/sched.h]
struct sighand_struct {
atomic_t count; //计数
struct k_sigaction action[_NSIG];
spinlock_t siglock;
wait_queue_head_t signalfd_wqh;
};
3.5 copy_signal
[-> fork.c]
static int copy_signal(unsigned long clone_flags, struct task_struct *tsk)
{
//结构体【见小节3.5.1】
struct signal_struct *sig;
//当设置CLONE_THREAD,则直接返回
if (clone_flags & CLONE_THREAD)
return 0;
//创建signal_struct结构体
sig = kmem_cache_zalloc(signal_cachep, GFP_KERNEL);
tsk->signal = sig;
...
sig->nr_threads = 1;
atomic_set(&sig->live, 1);
atomic_set(&sig->sigcnt, 1);
sig->thread_head = (struct list_head)LIST_HEAD_INIT(tsk->thread_node);
tsk->thread_node = (struct list_head)LIST_HEAD_INIT(sig->thread_head);
init_waitqueue_head(&sig->wait_chldexit);
sig->curr_target = tsk;
init_sigpending(&sig->shared_pending);
INIT_LIST_HEAD(&sig->posix_timers);
seqlock_init(&sig->stats_lock);
prev_cputime_init(&sig->prev_cputime);
hrtimer_init(&sig->real_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
sig->real_timer.function = it_real_fn;
task_lock(current->group_leader);
memcpy(sig->rlim, current->signal->rlim, sizeof sig->rlim);
task_unlock(current->group_leader);
posix_cpu_timers_init_group(sig);
tty_audit_fork(sig);
sched_autogroup_fork(sig);
//设置进程adj
sig->oom_score_adj = current->signal->oom_score_adj;
sig->oom_score_adj_min = current->signal->oom_score_adj_min;
sig->has_child_subreaper = current->signal->has_child_subreaper ||
current->signal->is_child_subreaper;
mutex_init(&sig->cred_guard_mutex);
return 0;
}
3.5.1 signal_struct结构体
[-> kernel/include/linux/sched.h]
struct signal_struct {
atomic_t sigcnt;
atomic_t live;
int nr_threads;
struct list_head thread_head;
wait_queue_head_t wait_chldexit; //用于wait4()
struct task_struct *curr_target; //当前线程组
struct sigpending shared_pending; //共享信号处理
int group_exit_code; //线程组的退出码
//当通知完相应进程,则会唤醒group_exit_task进程
//当分发fatal信号,除了group_exit_task进程之外的都会被停止
int notify_count;
struct task_struct *group_exit_task;
int group_stop_count;
unsigned int flags; //见SIGNAL_*系列
unsigned int is_child_subreaper:1;
unsigned int has_child_subreaper:1;
int posix_timer_id;
struct list_head posix_timers;
struct hrtimer real_timer;
struct pid *leader_pid;
ktime_t it_real_incr;
struct cpu_itimer it[2];
struct thread_group_cputimer cputimer;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
struct pid *tty_old_pgrp;
int leader; //是否为对话组的领头线程
struct tty_struct *tty; //当没有tty,则为NULL
seqlock_t stats_lock;
cputime_t utime, stime, cutime, cstime;
cputime_t gtime;
cputime_t cgtime;
struct prev_cputime prev_cputime;
unsigned long nvcsw, nivcsw, cnvcsw, cnivcsw;
unsigned long min_flt, maj_flt, cmin_flt, cmaj_flt;
unsigned long inblock, oublock, cinblock, coublock;
unsigned long maxrss, cmaxrss;
struct task_io_accounting ioac;
unsigned long long sum_sched_runtime;
struct rlimit rlim[RLIM_NLIMITS];
...
oom_flags_t oom_flags;
short oom_score_adj; //OOM killer的adj值
short oom_score_adj_min; //OOM killer的最小adj
struct mutex cred_guard_mutex;
};
signal_struct结构体并没有自己的锁,而是利用sighand_struct lock。
关于进程adj,可查看task->signal->oom_score_adj
3.6 copy_mm
[-> fork.c]
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
//结构体【见小节3.6.1】
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
#ifdef CONFIG_DETECT_HUNG_TASK
tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
#endif
tsk->mm = NULL;
tsk->active_mm = NULL;
//对于内核线程mm字段没空,则直接返回
oldmm = current->mm;
if (!oldmm)
return 0;
vmacache_flush(tsk); //初始化新的vmacache实体
if (clone_flags & CLONE_VM) {
//增加引用计数
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
//拷贝mm信息【见小节3.6.2】
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm; //设置mm字段
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}
该方法说明:
- 对于内核线程mm字段没空,则直接返回
- 当设置CLONE_VM,则增加mm_users计数
3.6.1 mm_struct
[-> kernel/include/linux/mm_types.h]
struct mm_struct {
struct vm_area_struct *mmap; //VMA列表
struct rb_root mm_rb;
u32 vmacache_seqnum; //每个线程的vma缓存
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif
unsigned long mmap_base; //mmap区域
unsigned long mmap_legacy_base; //自下而上分配的mmap区域
unsigned long task_size; //虚拟地址空间的大小
unsigned long highest_vm_end; //高端vma地址
pgd_t * pgd;
atomic_t mm_users; //使用该内存的进程个数
atomic_t mm_count; //结构体mm_struct的引用个数
atomic_long_t nr_ptes; //PTE页表
#if CONFIG_PGTABLE_LEVELS > 2
atomic_long_t nr_pmds; //PMD页表
#endif
int map_count; //VMA个数
spinlock_t page_table_lock; //用于保活页表和一些计数
struct rw_semaphore mmap_sem;
struct list_head mmlist;
unsigned long hiwater_rss; //RSS的高水位使用情况
unsigned long hiwater_vm; //高水位的虚拟内存使用情况
unsigned long total_vm; //页面映射的总数
unsigned long locked_vm; //PG_mlocked的页面数
unsigned long pinned_vm; //该计数永久增加
unsigned long shared_vm; //共享页面数(files)
unsigned long exec_vm; // VM_EXEC & ~VM_WRITE
unsigned long stack_vm; // VM_GROWSUP/DOWN
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; //用于/proc/PID/auxv
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
mm_context_t context; //内存上下文
unsigned long flags;
struct core_state *core_state; //支持coredump
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
struct task_struct __rcu *owner;
#endif
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and migrate
* pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
int numa_scan_seq; //用于防止两个线程设置pte_numa
#endif
#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)
/*
* An operation with batched TLB flushing is going on. Anything that
* can move process memory needs to flush the TLB when moving a
* PROT_NONE or PROT_NUMA mapped page.
*/
bool tlb_flush_pending;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_X86_INTEL_MPX
void __user *bd_addr; //绑定目录的地址
#endif
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
};
3.6.2 dup_mm
[-> fork.c]
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
int err;
mm = allocate_mm(); //分配内存
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk)) //初始化mm
goto fail_nomem;
err = dup_mmap(mm, oldmm); //拷贝内存信息
if (err)
goto free_pt;
mm->hiwater_rss = get_mm_rss(mm);
mm->hiwater_vm = mm->total_vm;
if (mm->binfmt && !try_module_get(mm->binfmt->module))
goto free_pt;
return mm;
free_pt:
mm->binfmt = NULL;
mmput(mm);
fail_nomem:
return NULL;
}
进程fork采用COW机制,实现的核心逻辑便在于内存拷贝过程会设置写保护。 具体实现在dup_mmap(),这里暂不展开,后续再专门讲解。
3.7 copy_namespaces
[-> kernel/kernel/nsproxy.c]
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
//一般情况都是进入该分支
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET)))) {
get_nsproxy(old_ns);
return 0;
}
if (!ns_capable(user_ns, CAP_SYS_ADMIN))
return -EPERM;
if ((flags & (CLONE_NEWIPC | CLONE_SYSVSEM)) ==
(CLONE_NEWIPC | CLONE_SYSVSEM))
return -EINVAL;
//创建新的用户空间
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
...
tsk->nsproxy = new_ns;
return 0;
}
3.7.1 nsproxy结构体
[-> kernel/include/linux/nsproxy.h]
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
};
3.8 copy_io
[-> fork.c]
static int copy_io(unsigned long clone_flags, struct task_struct *tsk)
{
#ifdef CONFIG_BLOCK
struct io_context *ioc = current->io_context;
struct io_context *new_ioc;
if (!ioc)
return 0;
if (clone_flags & CLONE_IO) {
ioc_task_link(ioc); //nr_tasks加1
tsk->io_context = ioc;
} else if (ioprio_valid(ioc->ioprio)) {
new_ioc = get_task_io_context(tsk, GFP_KERNEL, NUMA_NO_NODE);
if (unlikely(!new_ioc))
return -ENOMEM;
new_ioc->ioprio = ioc->ioprio;
put_io_context(new_ioc);
}
#endif
return 0;
}
- 当设置CLONE_IO,则父子进程间共享io context,nr_tasks加1
- 否则,创建新io_context结构体
3.8.1 io_context
[-> /kernel/include/linux/iocontext.h]
struct io_context {
atomic_long_t refcount;
atomic_t active_ref;
atomic_t nr_tasks; //进程个数
spinlock_t lock; //下面的成员都由该锁保护
unsigned short ioprio;
int nr_batch_requests; /* Number of requests left in the batch */
unsigned long last_waited; /* Time last woken after wait for request */
struct radix_tree_root icq_tree;
struct io_cq __rcu *icq_hint;
struct hlist_head icq_list;
struct work_struct release_work;
};
3.9 copy_thread_tls
[-> /kernel/arch/x86/kernel/process_64.c]
copy_thread_tls(clone_flags, stack_start, stack_size, p, tls);
int copy_thread_tls(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p, unsigned long tls)
{
int err;
struct pt_regs *childregs;
struct task_struct *me = current;
//获取寄存器信息记录到thread_struct结构体
p->thread.sp0 = (unsigned long)task_stack_page(p) + THREAD_SIZE;
childregs = task_pt_regs(p);
p->thread.sp = (unsigned long) childregs;
set_tsk_thread_flag(p, TIF_FORK);
p->thread.io_bitmap_ptr = NULL;
savesegment(gs, p->thread.gsindex);
p->thread.gs = p->thread.gsindex ? 0 : me->thread.gs;
savesegment(fs, p->thread.fsindex);
p->thread.fs = p->thread.fsindex ? 0 : me->thread.fs;
savesegment(es, p->thread.es);
savesegment(ds, p->thread.ds);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
if (unlikely(p->flags & PF_KTHREAD)) {
//内核线程
memset(childregs, 0, sizeof(struct pt_regs));
childregs->sp = (unsigned long)childregs;
childregs->ss = __KERNEL_DS;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
return 0;
}
//当前寄存器数据复制给新创建的子进程
*childregs = *current_pt_regs();
//子进程eax设置为0,故fork在子进程返回值为0
childregs->ax = 0;
if (sp)
childregs->sp = sp;
err = -ENOMEM;
if (unlikely(test_tsk_thread_flag(me, TIF_IO_BITMAP))) {
p->thread.io_bitmap_ptr = kmemdup(me->thread.io_bitmap_ptr,
IO_BITMAP_BYTES, GFP_KERNEL);
if (!p->thread.io_bitmap_ptr) {
p->thread.io_bitmap_max = 0;
return -ENOMEM;
}
set_tsk_thread_flag(p, TIF_IO_BITMAP);
}
//设置新的TLS
if (clone_flags & CLONE_SETTLS) {
err = do_arch_prctl(p, ARCH_SET_FS, tls);
if (err)
goto out;
}
err = 0;
out:
if (err && p->thread.io_bitmap_ptr) {
kfree(p->thread.io_bitmap_ptr);
p->thread.io_bitmap_max = 0;
}
return err;
}
设置子进程的寄存器等信息,从父进程拷贝thread_struct的sp0,sp,io_bitmap_ptr等成员变量值。
四. 总结
流程:
do_fork
_do_fork
copy_process
dup_task_struct
sched_fork
copy_xxx
alloc_pid
功能总结:
进程创建的核心实现在于copy_process()方法过程,而copy_process() 的主要实现在于copy_xxx()方法,根据不同的flags来决策采用何种拷贝方式。
- 执行dup_task_struct(),拷贝当前进程task_struct
- 检查进程数是否超过系统所允许的上限(默认32678)
- 执行sched_fork(),设置调度器相关信息,设置task进程状态为TASK_RUNNING,并分配CPU资源
- 执行copy_xxx(),拷贝进程的相关资源信息
- copy_semundo: 当设置CLONE_SYSVSEM,则父子进程间共享SEM_UNDO状态
- copy_files: 当设置CLONE_FILES,则只增加文件引用计数,不创建新的files_struct
- copy_fs: 当设置CLONE_FS,且没有执行exec, 则设置用户数加1
- copy_sighand: 当设置CLONE_SIGHAND, 则增加sighand->count计数
- copy_signal: 拷贝进程信号
- copy_mm:当设置CLONE_VM,则增加mm_users计数
- copy_namespaces:一般情况,不需要创建新用户空间
- copy_io: 当设置CLONE_IO,则父子进程间共享io context,增加nr_tasks计数
- copy_thread_tls:设置子进程的寄存器等信息,从父进程拷贝thread_struct的sp0,sp,io_bitmap_ptr等成员变量值
- 执行copy_thread_tls(), 拷贝子进程的内核栈信息
- 执行alloc_pid(),为新进程分配新pid
微信公众号 Gityuan | 微博 weibo.com/gityuan | 博客 留言区交流