基于Android 6.0的源码剖析, 本文深度剖析Binder IPC过程, 这绝对是一篇匠心巨作,从Java framework到Native,再到Linux Kernel,带你全程看Binder通信过程.
一. 引言
1.1 Binder架构的思考
Android内核是基于Linux系统, 而Linux现存多种进程间IPC方式:管道, 消息队列, 共享内存, 套接字, 信号量, 信号. 为什么Android非要用Binder来进行进程间通信呢. 从我个人的理解角度, 曾尝试着在知乎回答同样一个问题 为什么Android要采用Binder作为IPC机制?. 这是Gityuan第一次认认真真地在知乎上回答问题, 收到很多网友的点赞与回复, 让我很受鼓舞, 也决心分享更多优先地文章回报读者和粉丝, 为Android圈贡献自己的微薄之力。
在说到Binder架构之前, 先简单说说大家熟悉的TCP/IP的五层通信体系结构:
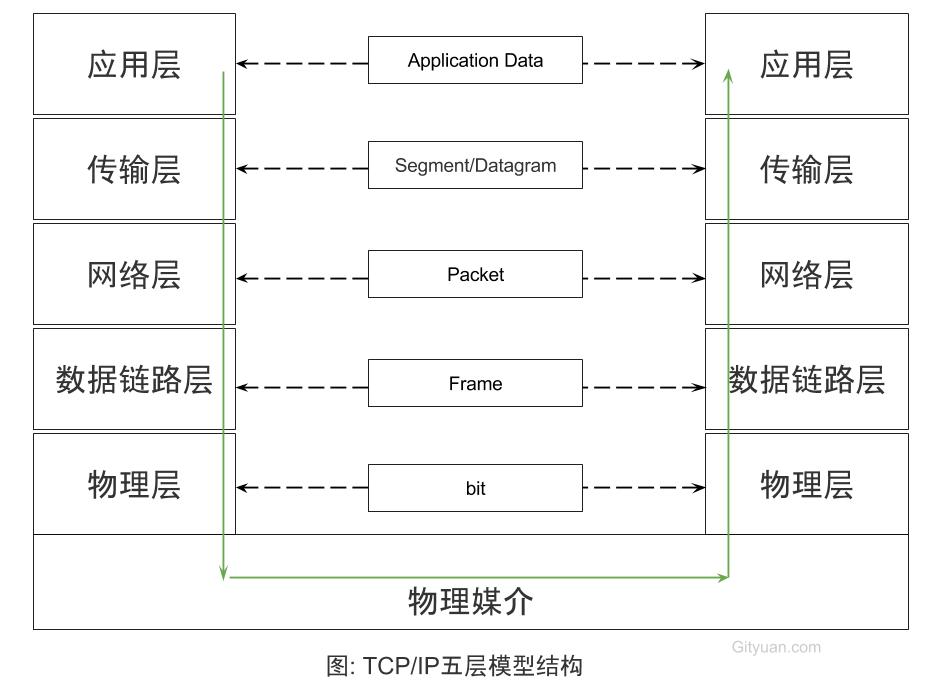
- 应用层: 直接为用户提供服务;
- 传输层: 传输的是报文(TCP数据)或者用户数据报(UDP数据)
- 网络层: 传输的是包(Packet), 例如路由器
- 数据链路层: 传输的是帧(Frame), 例如以太网交换机
- 物理层: 相邻节点间传输bit, 例如集线器,双绞线等
这是经典的五层TPC/IP协议体系, 这样分层设计的思想, 让每一个子问题都设计成一个独立的协议, 这协议的设计/分析/实现/测试都变得更加简单:
- 层与层具有独立性, 例如应用层可以使用传输层提供的功能而无需知晓其实现原理;
- 设计灵活, 层与层之间都定义好接口, 即便层内方法发生变化,只有接口不变, 对这个系统便毫无影响;
- 结构的解耦合, 让每一层可以用更适合的技术方案, 更合适的语言;
- 方便维护, 可分层调试和定位问题;
Binder架构也是采用分层架构设计, 每一层都有其不同的功能:
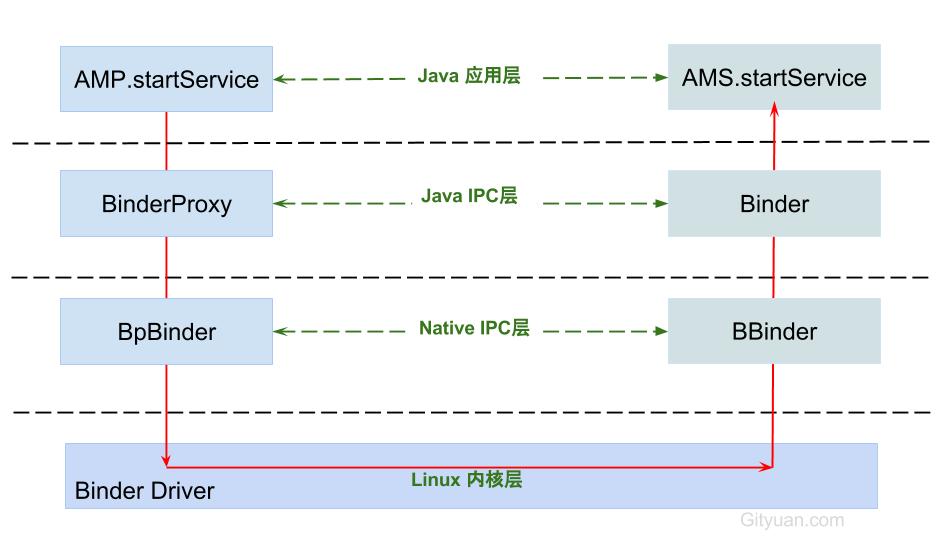
- Java应用层: 对于上层应用通过调用AMP.startService, 完全可以不用关心底层,经过层层调用,最终必然会调用到AMS.startService.
- Java IPC层: Binder通信是采用C/S架构, Android系统的基础架构便已设计好Binder在Java framework层的Binder客户类BinderProxy和服务类Binder;
- Native IPC层: 对于Native层,如果需要直接使用Binder(比如media相关), 则可以直接使用BpBinder和BBinder(当然这里还有JavaBBinder)即可, 对于上一层Java IPC的通信也是基于这个层面.
- Kernel物理层: 这里是Binder Driver, 前面3层都跑在用户空间,对于用户空间的内存资源是不共享的,每个Android的进程只能运行在自己进程所拥有的虚拟地址空间, 而内核空间却是可共享的. 真正通信的核心环节还是在Binder Driver.
1.2 分析起点
前面通过一个Binder系列-开篇来从源码讲解了Binder的各个层面, 但是Binder牵涉颇为广泛, 几乎是整个Android架构的顶梁柱, 虽说用了十几篇文章来阐述Binder的各个过程. 但依然还是没有将Binder IPC(进程间通信)的过程彻底说透.
Binder系统如此庞大, 那么这里需要寻求一个出发点来穿针引线, 一窥视Binder全貌. 那么本文将从全新的视角,以startService流程分析为例子来说说Binder所其作用. 首先在发起方进程调用AMP.startService,经过binder驱动,最终调用系统进程AMS.startService,如下图:
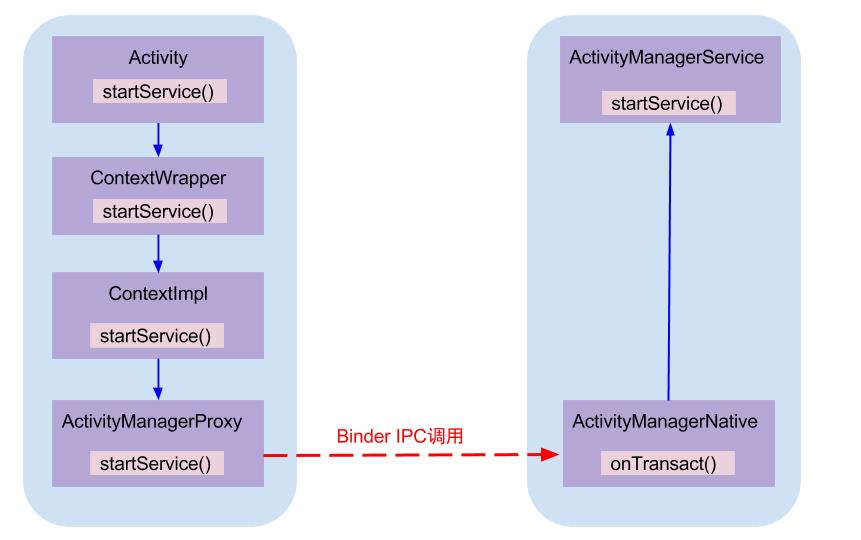
AMP和AMN都是实现了IActivityManager接口,AMS继承于AMN. 其中AMP作为Binder的客户端,运行在各个app所在进程, AMN(或AMS)运行在系统进程system_server.
1.3 Binder IPC原理
Binder通信采用C/S架构,从组件视角来说,包含Client、Server、ServiceManager以及binder驱动,其中ServiceManager用于管理系统中的各种服务。下面说说startService过程所涉及的Binder对象的架构图:
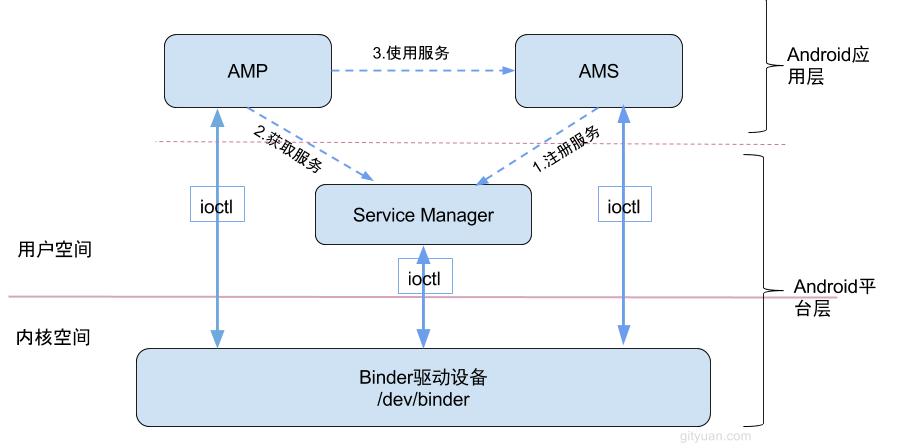
可以看出无论是注册服务和获取服务的过程都需要ServiceManager,需要注意的是此处的Service Manager是指Native层的ServiceManager(C++),并非指framework层的ServiceManager(Java)。ServiceManager是整个Binder通信机制的大管家,是Android进程间通信机制Binder的守护进程,Client端和Server端通信时都需要先获取Service Manager接口,才能开始通信服务, 当然查找到目标信息可以缓存起来则不需要每次都向ServiceManager请求。
图中Client/Server/ServiceManage之间的相互通信都是基于Binder机制。既然基于Binder机制通信,那么同样也是C/S架构,则图中的3大步骤都有相应的Client端与Server端。
- 注册服务:首先AMS注册到ServiceManager。该过程:AMS所在进程(system_server)是客户端,ServiceManager是服务端。
- 获取服务:Client进程使用AMS前,须先向ServiceManager中获取AMS的代理类AMP。该过程:AMP所在进程(app process)是客户端,ServiceManager是服务端。
- 使用服务: app进程根据得到的代理类AMP,便可以直接与AMS所在进程交互。该过程:AMP所在进程(app process)是客户端,AMS所在进程(system_server)是服务端。
图中的Client,Server,Service Manager之间交互都是虚线表示,是由于它们彼此之间不是直接交互的,而是都通过与Binder Driver进行交互的,从而实现IPC通信方式。其中Binder驱动位于内核空间,Client,Server,Service Manager位于用户空间。Binder驱动和Service Manager可以看做是Android平台的基础架构,而Client和Server是Android的应用层.
这3大过程每一次都是一个完整的Binder IPC过程, 接下来从源码角度, 仅介绍第3过程使用服务, 即展开AMP.startService是如何调用到AMS.startService的过程.
Tips: 如果你只想了解大致过程,并不打算细扣源码, 那么你可以略过通信过程源码分析, 仅看本文第一段落和最后段落也能对Binder所有理解.
二. 通信过程
2.1 AMP.startService
[-> ActivityManagerNative.java ::ActivityManagerProxy]
public ComponentName startService(IApplicationThread caller, Intent service,
String resolvedType, String callingPackage, int userId) throws RemoteException
{
//获取或创建Parcel对象【见小节2.2】
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
data.writeInterfaceToken(IActivityManager.descriptor);
data.writeStrongBinder(caller != null ? caller.asBinder() : null);
service.writeToParcel(data, 0);
//写入Parcel数据 【见小节2.3】
data.writeString(resolvedType);
data.writeString(callingPackage);
data.writeInt(userId);
//通过Binder传递数据【见小节2.5】
mRemote.transact(START_SERVICE_TRANSACTION, data, reply, 0);
//读取应答消息的异常情况
reply.readException();
//根据reply数据来创建ComponentName对象
ComponentName res = ComponentName.readFromParcel(reply);
//【见小节2.2.3】
data.recycle();
reply.recycle();
return res;
}
主要功能:
- 获取或创建两个Parcel对象,data用于发送数据,reply用于接收应答数据.
- 将startService相关数据都封装到Parcel对象data, 其中descriptor = “android.app.IActivityManager”;
- 通过Binder传递数据,并将应答消息写入reply;
- 读取reply应答消息的异常情况和组件对象;
2.2 Parcel.obtain
[-> Parcel.java]
public static Parcel obtain() {
final Parcel[] pool = sOwnedPool;
synchronized (pool) {
Parcel p;
//POOL_SIZE = 6
for (int i=0; i<POOL_SIZE; i++) {
p = pool[i];
if (p != null) {
pool[i] = null;
return p;
}
}
}
//当缓存池没有现成的Parcel对象,则直接创建[见流程2.2.1]
return new Parcel(0);
}
sOwnedPool是一个大小为6,存放着parcel对象的缓存池,这样设计的目标是用于节省每次都创建Parcel对象的开销。obtain()方法的作用:
- 先尝试从缓存池
sOwnedPool中查询是否存在缓存Parcel对象,当存在则直接返回该对象; - 如果没有可用的Parcel对象,则直接创建Parcel对象。
2.2.1 new Parcel
[-> Parcel.java]
private Parcel(long nativePtr) {
//初始化本地指针
init(nativePtr);
}
private void init(long nativePtr) {
if (nativePtr != 0) {
mNativePtr = nativePtr;
mOwnsNativeParcelObject = false;
} else {
// 首次创建,进入该分支[见流程2.2.2]
mNativePtr = nativeCreate();
mOwnsNativeParcelObject = true;
}
}
nativeCreate这是native方法,经过JNI进入native层, 调用android_os_Parcel_create()方法.
2.2.2 android_os_Parcel_create
[-> android_os_Parcel.cpp]
static jlong android_os_Parcel_create(JNIEnv* env, jclass clazz)
{
Parcel* parcel = new Parcel();
return reinterpret_cast<jlong>(parcel);
}
创建C++层的Parcel对象, 该对象指针强制转换为long型, 并保存到Java层的mNativePtr对象. 创建完Parcel对象利用Parcel对象写数据. 接下来以writeString为例.
2.2.3 Parcel.recycle
public final void recycle() {
//释放native parcel对象
freeBuffer();
final Parcel[] pool;
//根据情况来选择加入相应池
if (mOwnsNativeParcelObject) {
pool = sOwnedPool;
} else {
mNativePtr = 0;
pool = sHolderPool;
}
synchronized (pool) {
for (int i=0; i<POOL_SIZE; i++) {
if (pool[i] == null) {
pool[i] = this;
return;
}
}
}
}
将不再使用的Parcel对象放入缓存池,可回收重复利用,当缓存池已满则不再加入缓存池。这里有两个Parcel线程池,mOwnsNativeParcelObject变量来决定:
mOwnsNativeParcelObject=true, 即调用不带参数obtain()方法获取的对象, 回收时会放入sOwnedPool对象池;mOwnsNativeParcelObject=false, 即调用带nativePtr参数的obtain(long)方法获取的对象, 回收时会放入sHolderPool对象池;
2.3 writeString
[-> Parcel.java]
public final void writeString(String val) {
//[见流程2.3.1]
nativeWriteString(mNativePtr, val);
}
2.3.1 nativeWriteString
[-> android_os_Parcel.cpp]
static void android_os_Parcel_writeString(JNIEnv* env, jclass clazz, jlong nativePtr, jstring val)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
if (parcel != NULL) {
status_t err = NO_MEMORY;
if (val) {
const jchar* str = env->GetStringCritical(val, 0);
if (str) {
//[见流程2.3.2]
err = parcel->writeString16(
reinterpret_cast<const char16_t*>(str),
env->GetStringLength(val));
env->ReleaseStringCritical(val, str);
}
} else {
err = parcel->writeString16(NULL, 0);
}
if (err != NO_ERROR) {
signalExceptionForError(env, clazz, err);
}
}
}
2.3.2 writeString16
[-> Parcel.cpp]
status_t Parcel::writeString16(const char16_t* str, size_t len)
{
if (str == NULL) return writeInt32(-1);
status_t err = writeInt32(len);
if (err == NO_ERROR) {
len *= sizeof(char16_t);
uint8_t* data = (uint8_t*)writeInplace(len+sizeof(char16_t));
if (data) {
//数据拷贝到data所指向的位置
memcpy(data, str, len);
*reinterpret_cast<char16_t*>(data+len) = 0;
return NO_ERROR;
}
err = mError;
}
return err;
}
Tips: 除了writeString(),在Parcel.java中大量的native方法, 都是调用android_os_Parcel.cpp相对应的方法, 该方法再调用Parcel.cpp中对应的方法.
调用流程: Parcel.java –> android_os_Parcel.cpp –> Parcel.cpp.
frameworks/base/core/java/android/os/Parcel.java
frameworks/base/core/jni/android_os_Parcel.cpp
frameworks/native/libs/binder/Parcel.cpp
简单说,就是
2.4 mRemote究竟为何物
mRemote的出生,要出先说说ActivityManagerProxy对象(简称AMP)创建说起, AMP是通过ActivityManagerNative.getDefault()来获取的.
2.4.1 AMN.getDefault
[-> ActivityManagerNative.java]
static public IActivityManager getDefault() {
// [见流程2.4.2]
return gDefault.get();
}
gDefault的数据类型为Singleton<IActivityManager>, 这是一个单例模式, 接下来看看Singleto.get()的过程
2.4.2 gDefault.get
public abstract class Singleton<IActivityManager> {
public final IActivityManager get() {
synchronized (this) {
if (mInstance == null) {
//首次调用create()来获取AMP对象[见流程2.4.3]
mInstance = create();
}
return mInstance;
}
}
}
首次调用时需要创建,创建完之后保持到mInstance对象,之后可直接使用.
2.4.3 gDefault.create
private static final Singleton<IActivityManager> gDefault = new Singleton<IActivityManager>() {
protected IActivityManager create() {
//获取名为"activity"的服务
IBinder b = ServiceManager.getService("activity");
//创建AMP对象[见流程2.4.4]
IActivityManager am = asInterface(b);
return am;
}
};
文章Binder系列7—framework层分析,可知ServiceManager.getService(“activity”)返回的是指向目标服务AMS的代理对象BinderProxy对象,由该代理对象可以找到目标服务AMS所在进程
2.4.4 AMN.asInterface
[-> ActivityManagerNative.java]
public abstract class ActivityManagerNative extends Binder implements IActivityManager
{
static public IActivityManager asInterface(IBinder obj) {
if (obj == null) {
return null;
}
//此处obj = BinderProxy, descriptor = "android.app.IActivityManager"; [见流程2.4.5]
IActivityManager in = (IActivityManager)obj.queryLocalInterface(descriptor);
if (in != null) { //此处为null
return in;
}
//[见流程2.4.6]
return new ActivityManagerProxy(obj);
}
...
}
此时obj为BinderProxy对象, 记录着远程进程system_server中AMS服务的binder线程的handle.
2.4.5 queryLocalInterface
[Binder.java]
public class Binder implements IBinder {
//对于Binder对象的调用,则返回值不为空
public IInterface queryLocalInterface(String descriptor) {
//mDescriptor的初始化在attachInterface()过程中赋值
if (mDescriptor.equals(descriptor)) {
return mOwner;
}
return null;
}
}
//由上一小节[2.4.4]调用的流程便是此处,返回Null
final class BinderProxy implements IBinder {
//BinderProxy对象的调用, 则返回值为空
public IInterface queryLocalInterface(String descriptor) {
return null;
}
}
对于Binder IPC的过程中, 同一个进程的调用则会是asInterface()方法返回的便是本地的Binder对象;对于不同进程的调用则会是远程代理对象BinderProxy.
2.4.6 创建AMP
[-> ActivityManagerNative.java :: AMP]
class ActivityManagerProxy implements IActivityManager
{
public ActivityManagerProxy(IBinder remote)
{
mRemote = remote;
}
}
可知mRemote便是指向AMS服务的BinderProxy对象。
2.5 mRemote.transact
[-> Binder.java ::BinderProxy]
final class BinderProxy implements IBinder {
public boolean transact(int code, Parcel data, Parcel reply, int flags) throws RemoteException {
//用于检测Parcel大小是否大于800k
Binder.checkParcel(this, code, data, "Unreasonably large binder buffer");
//【见2.6】
return transactNative(code, data, reply, flags);
}
}
mRemote.transact()方法中的code=START_SERVICE_TRANSACTION, data保存了descriptor,caller, intent, resolvedType, callingPackage, userId这6项信息。
transactNative是native方法,经过jni调用android_os_BinderProxy_transact方法。
2.6 android_os_BinderProxy_transact
[-> android_util_Binder.cpp]
static jboolean android_os_BinderProxy_transact(JNIEnv* env, jobject obj,
jint code, jobject dataObj, jobject replyObj, jint flags)
{
...
//将java Parcel转为c++ Parcel
Parcel* data = parcelForJavaObject(env, dataObj);
Parcel* reply = parcelForJavaObject(env, replyObj);
//gBinderProxyOffsets.mObject中保存的是new BpBinder(handle)对象
IBinder* target = (IBinder*) env->GetLongField(obj, gBinderProxyOffsets.mObject);
...
//此处便是BpBinder::transact()【见小节2.7】
status_t err = target->transact(code, *data, reply, flags);
...
//最后根据transact执行具体情况,抛出相应的Exception
signalExceptionForError(env, obj, err, true , data->dataSize());
return JNI_FALSE;
}
gBinderProxyOffsets.mObject中保存的是BpBinder对象, 这是开机时Zygote调用AndroidRuntime::startReg方法来完成jni方法的注册.
其中register_android_os_Binder()过程就有一个初始并注册BinderProxy的操作,完成gBinderProxyOffsets的赋值过程. 接下来就进入该方法.
2.7 BpBinder.transact
[-> BpBinder.cpp]
status_t BpBinder::transact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
if (mAlive) {
// 【见小节2.8】
status_t status = IPCThreadState::self()->transact(
mHandle, code, data, reply, flags);
if (status == DEAD_OBJECT) mAlive = 0;
return status;
}
return DEAD_OBJECT;
}
IPCThreadState::self()采用单例模式,保证每个线程只有一个实例对象。
2.8 IPC.transact
[-> IPCThreadState.cpp]
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
status_t err = data.errorCheck(); //数据错误检查
flags |= TF_ACCEPT_FDS;
....
if (err == NO_ERROR) {
// 传输数据 【见小节2.9】
err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);
}
if (err != NO_ERROR) {
if (reply) reply->setError(err);
return (mLastError = err);
}
// 默认情况下,都是采用非oneway的方式, 也就是需要等待服务端的返回结果
if ((flags & TF_ONE_WAY) == 0) {
if (reply) {
//reply对象不为空 【见小节2.10】
err = waitForResponse(reply);
}else {
Parcel fakeReply;
err = waitForResponse(&fakeReply);
}
} else {
err = waitForResponse(NULL, NULL);
}
return err;
}
transact主要过程:
- 先执行writeTransactionData()已向Parcel数据类型的
mOut写入数据,此时mIn还没有数据; - 然后执行waitForResponse()方法,循环执行,直到收到应答消息. 调用talkWithDriver()跟驱动交互,收到应答消息,便会写入
mIn, 则根据收到的不同响应吗,执行相应的操作。
此处调用waitForResponse根据是否有设置TF_ONE_WAY的标记:
- 当已设置oneway时, 则调用waitForResponse(NULL, NULL);
- 当未设置oneway时, 则调用waitForResponse(reply) 或 waitForResponse(&fakeReply)
2.9 IPC.writeTransactionData
[-> IPCThreadState.cpp]
status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags,
int32_t handle, uint32_t code, const Parcel& data, status_t* statusBuffer)
{
binder_transaction_data tr;
tr.target.ptr = 0;
tr.target.handle = handle; // handle指向AMS
tr.code = code; // START_SERVICE_TRANSACTION
tr.flags = binderFlags; // 0
tr.cookie = 0;
tr.sender_pid = 0;
tr.sender_euid = 0;
const status_t err = data.errorCheck();
if (err == NO_ERROR) {
// data为startService相关信息
tr.data_size = data.ipcDataSize(); // mDataSize
tr.data.ptr.buffer = data.ipcData(); // mData指针
tr.offsets_size = data.ipcObjectsCount()*sizeof(binder_size_t); //mObjectsSize
tr.data.ptr.offsets = data.ipcObjects(); //mObjects指针
}
...
mOut.writeInt32(cmd); //cmd = BC_TRANSACTION
mOut.write(&tr, sizeof(tr)); //写入binder_transaction_data数据
return NO_ERROR;
}
将数据写入mOut
2.10 IPC.waitForResponse
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
int32_t cmd;
int32_t err;
while (1) {
if ((err=talkWithDriver()) < NO_ERROR) break; // 【见小节2.11】
err = mIn.errorCheck();
if (err < NO_ERROR) break; //当存在error则退出循环
//每当跟Driver交互一次,若mIn收到数据则往下执行一次BR命令
if (mIn.dataAvail() == 0) continue;
cmd = mIn.readInt32();
switch (cmd) {
case BR_TRANSACTION_COMPLETE:
//只有当不需要reply, 也就是oneway时 才会跳出循环,否则还需要等待.
if (!reply && !acquireResult) goto finish; break;
case BR_DEAD_REPLY:
err = DEAD_OBJECT; goto finish;
case BR_FAILED_REPLY:
err = FAILED_TRANSACTION; goto finish;
case BR_REPLY: ... goto finish;
default:
err = executeCommand(cmd); //【见小节2.12】
if (err != NO_ERROR) goto finish;
break;
}
}
finish:
if (err != NO_ERROR) {
if (reply) reply->setError(err); //将发送的错误代码返回给最初的调用者
}
return err;
}
在这个过程中, 收到以下任一BR_命令,处理后便会退出waitForResponse()的状态:
- BR_TRANSACTION_COMPLETE: binder驱动收到BC_TRANSACTION事件后的应答消息; 对于oneway transaction,当收到该消息,则完成了本次Binder通信;
- BR_DEAD_REPLY: 回复失败,往往是线程或节点为空. 则结束本次通信Binder;
- BR_FAILED_REPLY:回复失败,往往是transaction出错导致. 则结束本次通信Binder;
- BR_REPLY: Binder驱动向Client端发送回应消息; 对于非oneway transaction时,当收到该消息,则完整地完成本次Binder通信;
除了以上命令,其他命令的处理流程【见小节2.12】
2.11 IPC.talkWithDriver
//mOut有数据,mIn还没有数据。doReceive默认值为true
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
binder_write_read bwr;
const bool needRead = mIn.dataPosition() >= mIn.dataSize();
const size_t outAvail = (!doReceive || needRead) ? mOut.dataSize() : 0;
bwr.write_size = outAvail;
bwr.write_buffer = (uintptr_t)mOut.data();
if (doReceive && needRead) {
//接收数据缓冲区信息的填充。当收到驱动的数据,则写入mIn
bwr.read_size = mIn.dataCapacity();
bwr.read_buffer = (uintptr_t)mIn.data();
} else {
bwr.read_size = 0;
bwr.read_buffer = 0;
}
// 当同时没有输入和输出数据则直接返回
if ((bwr.write_size == 0) && (bwr.read_size == 0)) return NO_ERROR;
bwr.write_consumed = 0;
bwr.read_consumed = 0;
status_t err;
do {
//ioctl执行binder读写操作,经过syscall,进入Binder驱动。调用Binder_ioctl【小节3.1】
if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)
err = NO_ERROR;
else
err = -errno;
...
} while (err == -EINTR);
if (err >= NO_ERROR) {
if (bwr.write_consumed > 0) {
if (bwr.write_consumed < mOut.dataSize())
mOut.remove(0, bwr.write_consumed);
else
mOut.setDataSize(0);
}
if (bwr.read_consumed > 0) {
mIn.setDataSize(bwr.read_consumed);
mIn.setDataPosition(0);
}
return NO_ERROR;
}
return err;
}
binder_write_read结构体用来与Binder设备交换数据的结构, 通过ioctl与mDriverFD通信,是真正与Binder驱动进行数据读写交互的过程。
2.12 IPC.executeCommand
status_t IPCThreadState::executeCommand(int32_t cmd)
{
BBinder* obj;
RefBase::weakref_type* refs;
status_t result = NO_ERROR;
switch ((uint32_t)cmd) {
case BR_ERROR: ...
case BR_OK: ...
case BR_ACQUIRE: ...
case BR_RELEASE: ...
case BR_INCREFS: ...
case BR_TRANSACTION: ... //Binder驱动向Server端发送消息
case BR_DEAD_BINDER: ...
case BR_CLEAR_DEATH_NOTIFICATION_DONE: ...
case BR_NOOP: ...
case BR_SPAWN_LOOPER: ... //创建新binder线程
default: ...
}
}
再回到【小节2.11】,可知ioctl()方法经过syscall最终调用到Binder_ioctl()方法.
三、Binder driver
3.1 binder_ioctl
[-> Binder.c]
由【小节2.11】传递过出来的参数 cmd=BINDER_WRITE_READ
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
//当binder_stop_on_user_error>=2时,则该线程加入等待队列并进入休眠状态. 该值默认为0
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
...
binder_lock(__func__);
//查找或创建binder_thread结构体
thread = binder_get_thread(proc);
...
switch (cmd) {
case BINDER_WRITE_READ:
//【见小节3.2】
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
break;
...
}
ret = 0;
err:
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
binder_unlock(__func__);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
return ret;
}
首先,根据传递过来的文件句柄指针获取相应的binder_proc结构体, 再从中查找binder_thread,如果当前线程已经加入到proc的线程队列则直接返回, 如果不存在则创建binder_thread,并将当前线程添加到当前的proc.
- 当返回值为-ENOMEM,则意味着内存不足,往往会出现创建binder_thread对象失败;
- 当返回值为-EINVAL,则意味着CMD命令参数无效;
3.2 binder_ioctl_write_read
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
//将用户空间bwr结构体拷贝到内核空间
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
if (bwr.write_size > 0) {
//将数据放入目标进程【见小节3.3】
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
//当执行失败,则直接将内核bwr结构体写回用户空间,并跳出该方法
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user_preempt_disabled(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (bwr.read_size > 0) {
//读取自己队列的数据 【见小节3.5】
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
//当进程的todo队列有数据,则唤醒在该队列等待的进程
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
//当执行失败,则直接将内核bwr结构体写回用户空间,并跳出该方法
if (ret < 0) {
if (copy_to_user_preempt_disabled(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
此时arg是一个binder_write_read结构体,mOut数据保存在write_buffer,所以write_size>0,但此时read_size=0。首先,将用户空间bwr结构体拷贝到内核空间,然后执行binder_thread_write()操作.
3.3 binder_thread_write
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
//拷贝用户空间的cmd命令,此时为BC_TRANSACTION
if (get_user(cmd, (uint32_t __user *)ptr)) -EFAULT;
ptr += sizeof(uint32_t);
switch (cmd) {
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//拷贝用户空间的binder_transaction_data
if (copy_from_user(&tr, ptr, sizeof(tr))) return -EFAULT;
ptr += sizeof(tr);
// 见小节3.4】
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
}
...
}
*consumed = ptr - buffer;
}
return 0;
}
不断从binder_buffer所指向的地址获取cmd, 当只有BC_TRANSACTION或者BC_REPLY时, 则调用binder_transaction()来处理事务.
3.4 binder_transaction
发送的是BC_TRANSACTION时,此时reply=0。
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply){
struct binder_transaction *t;
struct binder_work *tcomplete;
binder_size_t *offp, *off_end;
binder_size_t off_min;
struct binder_proc *target_proc;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct list_head *target_list;
wait_queue_head_t *target_wait;
struct binder_transaction *in_reply_to = NULL;
if (reply) {
...
}else {
if (tr->target.handle) {
struct binder_ref *ref;
// 由handle 找到相应 binder_ref, 由binder_ref 找到相应 binder_node
ref = binder_get_ref(proc, tr->target.handle);
target_node = ref->node;
} else {
target_node = binder_context_mgr_node;
}
// 由binder_node 找到相应 binder_proc
target_proc = target_node->proc;
}
if (target_thread) {
e->to_thread = target_thread->pid;
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {
//首次执行target_thread为空
target_list = &target_proc->todo;
target_wait = &target_proc->wait;
}
t = kzalloc(sizeof(*t), GFP_KERNEL);
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
//非oneway的通信方式,把当前thread保存到transaction的from字段
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = task_euid(proc->tsk);
t->to_proc = target_proc; //此次通信目标进程为system_server
t->to_thread = target_thread;
t->code = tr->code; //此次通信code = START_SERVICE_TRANSACTION
t->flags = tr->flags; // 此次通信flags = 0
t->priority = task_nice(current);
//从目标进程target_proc中分配内存空间【3.4.1】
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
t->buffer->allow_user_free = 0;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
if (target_node)
binder_inc_node(target_node, 1, 0, NULL); //引用计数加1
//binder对象的偏移量
offp = (binder_size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof(void *)));
//分别拷贝用户空间的binder_transaction_data中ptr.buffer和ptr.offsets到目标进程的binder_buffer
copy_from_user(t->buffer->data,
(const void __user *)(uintptr_t)tr->data.ptr.buffer, tr->data_size);
copy_from_user(offp,
(const void __user *)(uintptr_t)tr->data.ptr.offsets, tr->offsets_size);
off_end = (void *)offp + tr->offsets_size;
for (; offp < off_end; offp++) {
struct flat_binder_object *fp;
fp = (struct flat_binder_object *)(t->buffer->data + *offp);
off_min = *offp + sizeof(struct flat_binder_object);
switch (fp->type) {
...
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
//处理引用计数情况
struct binder_ref *ref = binder_get_ref(proc, fp->handle);
if (ref->node->proc == target_proc) {
if (fp->type == BINDER_TYPE_HANDLE)
fp->type = BINDER_TYPE_BINDER;
else
fp->type = BINDER_TYPE_WEAK_BINDER;
fp->binder = ref->node->ptr;
fp->cookie = ref->node->cookie;
binder_inc_node(ref->node, fp->type == BINDER_TYPE_BINDER, 0, NULL);
} else {
struct binder_ref *new_ref;
new_ref = binder_get_ref_for_node(target_proc, ref->node);
fp->handle = new_ref->desc;
binder_inc_ref(new_ref, fp->type == BINDER_TYPE_HANDLE, NULL);
}
} break;
...
default:
return_error = BR_FAILED_REPLY;
goto err_bad_object_type;
}
}
if (reply) {
//BC_REPLY的过程
binder_pop_transaction(target_thread, in_reply_to);
} else if (!(t->flags & TF_ONE_WAY)) {
//BC_TRANSACTION 且 非oneway,则设置事务栈信息
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
} else {
//BC_TRANSACTION 且 oneway,则加入异步todo队列
if (target_node->has_async_transaction) {
target_list = &target_node->async_todo;
target_wait = NULL;
} else
target_node->has_async_transaction = 1;
}
//将BINDER_WORK_TRANSACTION添加到目标队列,即target_proc->todo
t->work.type = BINDER_WORK_TRANSACTION;
list_add_tail(&t->work.entry, target_list);
//将BINDER_WORK_TRANSACTION_COMPLETE添加到当前线程队列,即thread->todo
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
//唤醒等待队列,本次通信的目标队列为target_proc->wait
if (target_wait)
wake_up_interruptible(target_wait);
return;
}
主要功能:
- 查询目标进程的过程: handle -> binder_ref -> binder_node -> binder_proc
- 将
BINDER_WORK_TRANSACTION添加到目标队列target_list:- call事务, 则目标队列target_list=
target_proc->todo; - reply事务,则目标队列target_list=
target_thread->todo; - async事务,则目标队列target_list=
target_node->async_todo.
- call事务, 则目标队列target_list=
- 数据拷贝
- 将用户空间binder_transaction_data中ptr.buffer和ptr.offsets拷贝到目标进程的binder_buffer->data;
- 这就是只拷贝一次的真理所在;
- 设置事务栈信息
- BC_TRANSACTION且非oneway, 则将当前事务添加到thread->transaction_stack;
- 事务分发过程:
- 将
BINDER_WORK_TRANSACTION添加到目标队列(此时为target_proc->todo队列); - 将
BINDER_WORK_TRANSACTION_COMPLETE添加到当前线程thread->todo队列;
- 将
- 唤醒目标进程target_proc开始执行事务。
该方法中proc/thread是指当前发起方的进程信息,而binder_proc是指目标接收端进程。 此时当前线程thread的todo队列已经有事务, 接下来便会进入binder_thread_read来处理相关的事务.
3.4.1 binder_alloc_buf
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size, size_t offsets_size, int is_async)
{
struct rb_node *n = proc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void *has_page_addr;
void *end_page_addr;
size_t size;
..
size = ALIGN(data_size, sizeof(void *)) + ALIGN(offsets_size, sizeof(void *));
if (is_async && proc->free_async_space < size + sizeof(struct binder_buffer)) {
return NULL; // 剩余可用的异步空间,小于所需的大小
}
while (n) { //从binder_buffer的红黑树中查找大小相等的buffer块
buffer = rb_entry(n, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
...
if (n == NULL) {
buffer = rb_entry(best_fit, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
}
has_page_addr =(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK);
if (n == NULL) {
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size)
buffer_size = size;
else
buffer_size = size + sizeof(struct binder_buffer);
}
//末端地址
end_page_addr = (void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
...
//分配物理页
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL))
return NULL;
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
binder_insert_allocated_buffer(proc, buffer);
if (buffer_size != size) {
struct binder_buffer *new_buffer = (void *)buffer->data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
binder_insert_free_buffer(proc, new_buffer);
}
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;
if (is_async) { //调整异步可用内存空间大小
proc->free_async_space -= size + sizeof(struct binder_buffer);
}
return buffer;
}
3.5 binder_thread_read
binder_thread_read(){
//当已使用字节数为0时,将BR_NOOP响应码放入指针ptr
if (*consumed == 0) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
retry:
//binder_transaction()已设置transaction_stack不为空,则wait_for_proc_work为false.
wait_for_proc_work = thread->transaction_stack == NULL &&
list_empty(&thread->todo);
thread->looper |= BINDER_LOOPER_STATE_WAITING;
if (wait_for_proc_work)
proc->ready_threads++; //进程中空闲binder线程加1
//只有当前线程todo队列为空,并且transaction_stack也为空,才会开始处于当前进程的事务
if (wait_for_proc_work) {
if (non_block) {
...
} else
//当进程todo队列没有数据,则进入休眠等待状态
ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread));
} else {
if (non_block) {
...
} else
//当线程todo队列有数据则执行往下执行;当线程todo队列没有数据,则进入休眠等待状态
ret = wait_event_freezable(thread->wait, binder_has_thread_work(thread));
}
if (wait_for_proc_work)
proc->ready_threads--; //退出等待状态, 则进程中空闲binder线程减1
thread->looper &= ~BINDER_LOOPER_STATE_WAITING;
...
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
//先从线程todo队列获取事务数据
if (!list_empty(&thread->todo)) {
w = list_first_entry(&thread->todo, struct binder_work, entry);
// 线程todo队列没有数据, 则从进程todo对获取事务数据
} else if (!list_empty(&proc->todo) && wait_for_proc_work) {
w = list_first_entry(&proc->todo, struct binder_work, entry);
} else {
//没有数据,则返回retry
if (ptr - buffer == 4 &&
!(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN))
goto retry;
break;
}
switch (w->type) {
case BINDER_WORK_TRANSACTION:
//获取transaction数据
t = container_of(w, struct binder_transaction, work);
break;
case BINDER_WORK_TRANSACTION_COMPLETE:
cmd = BR_TRANSACTION_COMPLETE;
//将BR_TRANSACTION_COMPLETE写入*ptr,并跳出循环。
put_user(cmd, (uint32_t __user *)ptr);
list_del(&w->entry);
kfree(w);
break;
case BINDER_WORK_NODE: ... break;
case BINDER_WORK_DEAD_BINDER:
case BINDER_WORK_DEAD_BINDER_AND_CLEAR:
case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: ... break;
}
//只有BINDER_WORK_TRANSACTION命令才能继续往下执行
if (!t)
continue;
if (t->buffer->target_node) {
//获取目标node
struct binder_node *target_node = t->buffer->target_node;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
t->saved_priority = task_nice(current);
...
cmd = BR_TRANSACTION; //设置命令为BR_TRANSACTION
} else {
tr.target.ptr = NULL;
tr.cookie = NULL;
cmd = BR_REPLY; //设置命令为BR_REPLY
}
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = t->sender_euid;
if (t->from) {
struct task_struct *sender = t->from->proc->tsk;
//当非oneway的情况下,将调用者进程的pid保存到sender_pid
tr.sender_pid = task_tgid_nr_ns(sender,
current->nsproxy->pid_ns);
} else {
//当oneway的的情况下,则该值为0
tr.sender_pid = 0;
}
tr.data_size = t->buffer->data_size;
tr.offsets_size = t->buffer->offsets_size;
tr.data.ptr.buffer = (void *)t->buffer->data + proc->user_buffer_offset;
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size, sizeof(void *));
//将cmd和数据写回用户空间
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
if (copy_to_user(ptr, &tr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
list_del(&t->work.entry);
t->buffer->allow_user_free = 1;
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;
} else {
t->buffer->transaction = NULL;
kfree(t); //通信完成,则运行释放
}
break;
}
done:
*consumed = ptr - buffer;
//当满足请求线程加已准备线程数等于0,已启动线程数小于最大线程数(15),
//且looper状态为已注册或已进入时创建新的线程。
if (proc->requested_threads + proc->ready_threads == 0 &&
proc->requested_threads_started < proc->max_threads &&
(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED))) {
proc->requested_threads++;
// 生成BR_SPAWN_LOOPER命令,用于创建新的线程
put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer);
}
return 0;
}
该方法功能说明:
此处wait_for_proc_work是指当前线程todo队列为空,并且transaction_stack也为空,该值为true.
- 当wait_for_proc_work = false, 则进入线程的等待队列thread->wait, 直到thread->todo队列有事务才往下执行;
- 获取并处理thread->todo队列中的事务;将相应的cmd和数据写回用户空间.
- 当wait_for_proc_work = true, 则进入线程的等待队列proc->wait, 直到proc->todo队列有事务才往下执行;
- 获取并处理proc->todo队列中的事务;将相应的cmd和数据写回用户空间.
到这里,可能有人好奇,对于[小节3.4]介绍了target_list有3种, 这里只会处理前2种:thread->todo, proc->todo.那么对于 target_node->async_todo的处理过程时间呢? [见小节5.4]
3.6 下一步何去何从
- 执行完binder_thread_write方法后, 通过binder_transaction()首先写入
BINDER_WORK_TRANSACTION_COMPLETE写入当前线程. - 这时bwr.read_size > 0, 回到binder_ioctl_write_read方法, 便开始执行binder_thread_read();
- 在binder_thread_read()方法, 将获取cmd=BR_TRANSACTION_COMPLETE, 再将cmd和数据写回用户空间;
- 一次Binder_ioctl完成,接着回调用户空间方法talkWithDriver(),刚才的数据以写入mIn.
- 这时mIn有可读数据, 回到【小节2.10】IPC.waitForResponse()方法,完成BR_TRANSACTION_COMPLETE过程. 如果本次transaction采用非oneway方式, 这次Binder通信便完成, 否则还是要等待Binder服务端的返回。
对于startService过程, 采用的便是非oneway方式,那么发起者进程还会继续停留在waitForResponse()方法,继续talkWithDriver(),然后休眠在binder_thread_read()的wait_event_freezable()过程,等待当前线程的todo队列有数据的到来,即等待收到BR_REPLY消息.
由于在前面binder_transaction()除了向自己所在线程写入了BINDER_WORK_TRANSACTION_COMPLETE, 还向目标进程(此处为system_server)写入了BINDER_WORK_TRANSACTION命令,那么接下里介绍system_server进程的工作。
四. 回到用户空间
system_server的binder线程是如何运转的,那么就需要从Binder线程的创建开始说起,
Binder线程的创建有两种方式:
- ProcessState::self()->startThreadPool();
- IPCThreadState::self()->joinThreadPool();
从文章addService 小节4.1,可知,调用链如下:
startThreadPool()过程会创建新Binder线程,再经过层层调用也会进入joinThreadPool()方法。
system_server的binder线程从IPC.joinThreadPool –> IPC.getAndExecuteCommand() -> IPC.talkWithDriver() ,但talkWithDriver收到事务之后, 便进入IPC.executeCommand()方法。
接下来从joinThreadPool说起:
4.1 IPC.joinThreadPool
void IPCThreadState::joinThreadPool(bool isMain)
{
mOut.writeInt32(isMain ? BC_ENTER_LOOPER : BC_REGISTER_LOOPER);
set_sched_policy(mMyThreadId, SP_FOREGROUND);
status_t result;
do {
processPendingDerefs(); //处理对象引用
result = getAndExecuteCommand();//获取并执行命令【见小节4.2】
if (result < NO_ERROR && result != TIMED_OUT && result != -ECONNREFUSED && result != -EBADF) {
ALOGE("getAndExecuteCommand(fd=%d) returned unexpected error %d, aborting",
mProcess->mDriverFD, result);
abort();
}
//对于binder非主线程不再使用,则退出
if(result == TIMED_OUT && !isMain) {
break;
}
} while (result != -ECONNREFUSED && result != -EBADF);
mOut.writeInt32(BC_EXIT_LOOPER);
talkWithDriver(false);
}
4.2 IPC.getAndExecuteCommand
status_t IPCThreadState::getAndExecuteCommand()
{
status_t result;
int32_t cmd;
result = talkWithDriver(); //该Binder Driver进行交互
if (result >= NO_ERROR) {
size_t IN = mIn.dataAvail();
if (IN < sizeof(int32_t)) return result;
cmd = mIn.readInt32(); //读取命令
pthread_mutex_lock(&mProcess->mThreadCountLock);
mProcess->mExecutingThreadsCount++;
pthread_mutex_unlock(&mProcess->mThreadCountLock);
result = executeCommand(cmd); //【见小节4.3】
pthread_mutex_lock(&mProcess->mThreadCountLock);
mProcess->mExecutingThreadsCount--;
pthread_cond_broadcast(&mProcess->mThreadCountDecrement);
pthread_mutex_unlock(&mProcess->mThreadCountLock);
set_sched_policy(mMyThreadId, SP_FOREGROUND);
}
return result;
}
此时system_server的binder线程空闲便是停留在binder_thread_read()方法来处理进程/线程新的事务。
由【小节3.4】可知收到的是BINDER_WORK_TRANSACTION命令, 再经过inder_thread_read()后生成命令cmd=BR_TRANSACTION.再将cmd和数据写回用户空间。
4.3 IPC.executeCommand
status_t IPCThreadState::executeCommand(int32_t cmd)
{
BBinder* obj;
RefBase::weakref_type* refs;
status_t result = NO_ERROR;
switch ((uint32_t)cmd) {
case BR_TRANSACTION:
{
binder_transaction_data tr;
result = mIn.read(&tr, sizeof(tr)); //读取mIn数据
if (result != NO_ERROR) break;
Parcel buffer;
//当buffer对象回收时,则会调用freeBuffer来回收内存【见小节4.3.1】
buffer.ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), freeBuffer, this);
const pid_t origPid = mCallingPid;
const uid_t origUid = mCallingUid;
const int32_t origStrictModePolicy = mStrictModePolicy;
const int32_t origTransactionBinderFlags = mLastTransactionBinderFlags;
//设置调用者的pid和uid
mCallingPid = tr.sender_pid;
mCallingUid = tr.sender_euid;
mLastTransactionBinderFlags = tr.flags;
int curPrio = getpriority(PRIO_PROCESS, mMyThreadId);
if (gDisableBackgroundScheduling) {
... //不进入此分支
} else {
if (curPrio >= ANDROID_PRIORITY_BACKGROUND) {
set_sched_policy(mMyThreadId, SP_BACKGROUND);
}
}
Parcel reply;
status_t error;
if (tr.target.ptr) {
//尝试通过弱引用获取强引用
if (reinterpret_cast<RefBase::weakref_type*>(
tr.target.ptr)->attemptIncStrong(this)) {
// tr.cookie里存放的是BBinder子类JavaBBinder [见流程4.4]
error = reinterpret_cast<BBinder*>(tr.cookie)->transact(tr.code, buffer,
&reply, tr.flags);
reinterpret_cast<BBinder*>(tr.cookie)->decStrong(this);
} else {
error = UNKNOWN_TRANSACTION;
}
} else {
error = the_context_object->transact(tr.code, buffer, &reply, tr.flags);
}
if ((tr.flags & TF_ONE_WAY) == 0) {
if (error < NO_ERROR) reply.setError(error);
//对于非oneway, 需要reply通信过程,则向Binder驱动发送BC_REPLY命令【见小节4.3.1】
sendReply(reply, 0);
}
//恢复pid和uid信息
mCallingPid = origPid;
mCallingUid = origUid;
...
}
break;
case ...
default:
result = UNKNOWN_ERROR;
break;
}
if (result != NO_ERROR) {
mLastError = result;
}
return result;
}
- 对于oneway的场景, 执行完本次transact()则全部结束.
- 对于非oneway, 需要reply的通信过程,则向Binder驱动发送BC_REPLY命令【见小节5.1】
4.3.1 ipcSetDataReference
[-> Parcel.cpp]
void Parcel::ipcSetDataReference(const uint8_t* data, size_t dataSize,
const binder_size_t* objects, size_t objectsCount, release_func relFunc, void* relCookie)
{
binder_size_t minOffset = 0;
freeDataNoInit(); //【见小节4.3.2】
mError = NO_ERROR;
mData = const_cast<uint8_t*>(data);
mDataSize = mDataCapacity = dataSize;
mDataPos = 0;
mObjects = const_cast<binder_size_t*>(objects);
mObjectsSize = mObjectsCapacity = objectsCount;
mNextObjectHint = 0;
mOwner = relFunc;
mOwnerCookie = relCookie;
for (size_t i = 0; i < mObjectsSize; i++) {
binder_size_t offset = mObjects[i];
if (offset < minOffset) {
mObjectsSize = 0;
break;
}
minOffset = offset + sizeof(flat_binder_object);
}
scanForFds();
}
该方法的功能,Parcel成员变量说明:
- mData:parcel数据起始地址
- mDataSize:parcel数据大小
- mObjects:flat_binder_object地址偏移量
- mObjectsSize:parcel中flat_binder_object个数
- mOwner:释放函数freebuffer
- mOwnerCookie:释放函数所需信息
4.3.2 freeDataNoInit
[-> Parcel.cpp]
void Parcel::freeDataNoInit()
{
if (mOwner) {
mOwner(this, mData, mDataSize, mObjects, mObjectsSize, mOwnerCookie);
} else { //mOwner为空, 进入该分支
releaseObjects(); //【见小节4.3.3】
if (mData) {
pthread_mutex_lock(&gParcelGlobalAllocSizeLock);
if (mDataCapacity <= gParcelGlobalAllocSize) {
gParcelGlobalAllocSize = gParcelGlobalAllocSize - mDataCapacity;
} else {
gParcelGlobalAllocSize = 0;
}
if (gParcelGlobalAllocCount > 0) {
gParcelGlobalAllocCount--;
}
pthread_mutex_unlock(&gParcelGlobalAllocSizeLock);
free(mData);
}
if (mObjects) free(mObjects);
}
}
4.3.3 releaseObjects
void Parcel::releaseObjects()
{
const sp<ProcessState> proc(ProcessState::self());
size_t i = mObjectsSize;
uint8_t* const data = mData;
binder_size_t* const objects = mObjects;
while (i > 0) {
i--;
const flat_binder_object* flat
= reinterpret_cast<flat_binder_object*>(data+objects[i]);
//【见小节4.3.4】
release_object(proc, *flat, this, &mOpenAshmemSize);
}
}
4.3.4 release_object
static void release_object(const sp<ProcessState>& proc,
const flat_binder_object& obj, const void* who, size_t* outAshmemSize)
{
switch (obj.type) {
case BINDER_TYPE_BINDER:
if (obj.binder) {
reinterpret_cast<IBinder*>(obj.cookie)->decStrong(who);
}
return;
case BINDER_TYPE_WEAK_BINDER:
if (obj.binder)
reinterpret_cast<RefBase::weakref_type*>(obj.binder)->decWeak(who);
return;
case BINDER_TYPE_HANDLE: {
const sp<IBinder> b = proc->getStrongProxyForHandle(obj.handle);
if (b != NULL) {
b->decStrong(who);
}
return;
}
case BINDER_TYPE_WEAK_HANDLE: {
const wp<IBinder> b = proc->getWeakProxyForHandle(obj.handle);
if (b != NULL) b.get_refs()->decWeak(who);
return;
}
case BINDER_TYPE_FD: {
...
return;
}
}
}
根据flat_binder_object的类型,来决定减少相应的强弱引用。
4.3.5 ~Parcel
[-> Parcel.cpp]
当[小节4.3]executeCommand执行完成后, 便会释放局部变量Parcel buffer,则会析构Parcel。
Parcel::~Parcel()
{
freeDataNoInit();
}
void Parcel::freeDataNoInit()
{
if (mOwner) { //此处mOwner等于freeBuffer 【见小节4.3.6】
mOwner(this, mData, mDataSize, mObjects, mObjectsSize, mOwnerCookie);
} else {
...
}
}
接下来,进入IPC的freeBuffer过程。
4.3.6 freeBuffer
[-> IPCThreadState.cpp]
void IPCThreadState::freeBuffer(Parcel* parcel, const uint8_t* data,
size_t /*dataSize*/,
const binder_size_t* /*objects*/,
size_t /*objectsSize*/, void* /*cookie*/)
{
if (parcel != NULL) parcel->closeFileDescriptors();
IPCThreadState* state = self();
state->mOut.writeInt32(BC_FREE_BUFFER);
state->mOut.writePointer((uintptr_t)data);
}
向Binder驱动写入BC_FREE_BUFFER命令。
4.4 BBinder.transact
[-> Binder.cpp ::BBinder ]
status_t BBinder::transact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
data.setDataPosition(0);
status_t err = NO_ERROR;
switch (code) {
case PING_TRANSACTION:
reply->writeInt32(pingBinder());
break;
default:
err = onTransact(code, data, reply, flags); //【见流程4.5】
break;
}
if (reply != NULL) {
reply->setDataPosition(0);
}
return err;
}
4.5 JavaBBinder.onTransact
[-> android_util_Binder.cpp]
virtual status_t onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags = 0)
{
JNIEnv* env = javavm_to_jnienv(mVM);
IPCThreadState* thread_state = IPCThreadState::self();
//调用Binder.execTransact [见流程4.6]
jboolean res = env->CallBooleanMethod(mObject, gBinderOffsets.mExecTransact,
code, reinterpret_cast<jlong>(&data), reinterpret_cast<jlong>(reply), flags);
jthrowable excep = env->ExceptionOccurred();
if (excep) {
res = JNI_FALSE;
//发生异常, 则清理JNI本地引用
env->DeleteLocalRef(excep);
}
...
return res != JNI_FALSE ? NO_ERROR : UNKNOWN_TRANSACTION;
}
还记得AndroidRuntime::startReg过程吗, 其中有一个过程便是register_android_os_Binder(),该过程会把gBinderOffsets.mExecTransact便是Binder.java中的execTransact()方法.详见见Binder系列7—framework层分析文章中的第二节初始化的过程.
另外,此处mObject是在服务注册addService过程,会调用writeStrongBinder方法, 将Binder对象传入了JavaBBinder构造函数的参数, 最终赋值给mObject. 在本次通信过程中Object为ActivityManagerNative对象.
此处斗转星移, 从C++代码回到了Java代码. 进入AMN.execTransact, 由于AMN继续于Binder对象, 接下来进入Binder.execTransact
4.6 Binder.execTransact
[Binder.java]
private boolean execTransact(int code, long dataObj, long replyObj,
int flags) {
Parcel data = Parcel.obtain(dataObj);
Parcel reply = Parcel.obtain(replyObj);
boolean res;
try {
// 调用子类AMN.onTransact方法 [见流程4.7]
res = onTransact(code, data, reply, flags);
} catch (RemoteException e) {
if ((flags & FLAG_ONEWAY) != 0) {
...
} else {
//非oneway的方式,则会将异常写回reply
reply.setDataPosition(0);
reply.writeException(e);
}
res = true;
} catch (RuntimeException e) {
if ((flags & FLAG_ONEWAY) != 0) {
...
} else {
reply.setDataPosition(0);
reply.writeException(e);
}
res = true;
} catch (OutOfMemoryError e) {
RuntimeException re = new RuntimeException("Out of memory", e);
reply.setDataPosition(0);
reply.writeException(re);
res = true;
}
reply.recycle();
data.recycle();
return res;
}
当发生RemoteException, RuntimeException, OutOfMemoryError, 对于非oneway的情况下都会把异常传递给调用者.
4.7 AMN.onTransact
[-> ActivityManagerNative.java]
public boolean onTransact(int code, Parcel data, Parcel reply, int flags)
throws RemoteException {
switch (code) {
...
case START_SERVICE_TRANSACTION: {
data.enforceInterface(IActivityManager.descriptor);
IBinder b = data.readStrongBinder();
//生成ApplicationThreadNative的代理对象,即ApplicationThreadProxy对象
IApplicationThread app = ApplicationThreadNative.asInterface(b);
Intent service = Intent.CREATOR.createFromParcel(data);
String resolvedType = data.readString();
String callingPackage = data.readString();
int userId = data.readInt();
//调用ActivityManagerService的startService()方法【见流程4.8】
ComponentName cn = startService(app, service, resolvedType, callingPackage, userId);
reply.writeNoException();
ComponentName.writeToParcel(cn, reply);
return true;
}
}
4.8 AMS.startService
public ComponentName startService(IApplicationThread caller, Intent service,
String resolvedType, String callingPackage, int userId)
throws TransactionTooLargeException {
synchronized(this) {
...
ComponentName res = mServices.startServiceLocked(caller, service,
resolvedType, callingPid, callingUid, callingPackage, userId);
Binder.restoreCallingIdentity(origId);
return res;
}
}
历经千山万水, 总算是进入了AMS.startService. 当system_server收到BR_TRANSACTION的过程后,通信并没有完全结束,还需将服务启动完成的回应消息 告诉给发起端进程。
五. Reply流程
还记得前面【小节2.10】IPC.waitForResponse()过程,对于非oneway的方式,还仍在一直等待system_server这边的响应呢,只有收到BR_REPLY,或者BR_DEAD_REPLY,或者BR_FAILED_REPLY,再或许其他BR_命令执行出错的情况下,该waitForResponse()才会退出。
BR_REPLY命令是如何来的呢?【小节4.3】IPC.executeCommand()过程处理完BR_TRANSACTION命令的同时,还会通过sendReply()向Binder Driver发送BC_REPLY消息,接下来从该方法说起。
5.1 IPC.sendReply
status_t IPCThreadState::sendReply(const Parcel& reply, uint32_t flags)
{
status_t err;
status_t statusBuffer;
//[见小节2.10]
err = writeTransactionData(BC_REPLY, flags, -1, 0, reply, &statusBuffer);
if (err < NO_ERROR) return err;
//[见小节5.3]
return waitForResponse(NULL, NULL);
}
先将数据写入mOut;再进waitForResponse,等待应答,此时同理也是等待BR_TRANSACTION_COMPLETE。 同理经过IPC.talkWithDriver -> binder_ioctl -> binder_ioctl_write_read -> binder_thread_write, 再就是进入binder_transaction方法。
5.2 BC_REPLY
// reply =true
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
...
if (reply) {
in_reply_to = thread->transaction_stack; //接收端的事务栈
...
thread->transaction_stack = in_reply_to->to_parent;
target_thread = in_reply_to->from; //发起端的线程
//发起端线程不能为空
if (target_thread == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
//发起端线程的事务栈 要等于 接收端的事务栈
if (target_thread->transaction_stack != in_reply_to) {
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
target_thread = NULL;
goto err_dead_binder;
}
target_proc = target_thread->proc; //发起端的进程
} else {
...
}
if (target_thread) {
//发起端的线程
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {
...
}
t = kzalloc(sizeof(*t), GFP_KERNEL);
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
...
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL; //进入该分支
t->sender_euid = task_euid(proc->tsk);
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
t->priority = task_nice(current);
// 发起端进程分配buffer
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
...
t->buffer->allow_user_free = 0;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
if (target_node)
binder_inc_node(target_node, 1, 0, NULL);
//分别拷贝用户空间的binder_transaction_data中ptr.buffer和ptr.offsets到内核
copy_from_user(t->buffer->data,
(const void __user *)(uintptr_t)tr->data.ptr.buffer, tr->data_size);
copy_from_user(offp,
(const void __user *)(uintptr_t)tr->data.ptr.offsets, tr->offsets_size);
...
if (reply) {
binder_pop_transaction(target_thread, in_reply_to);
} else if (!(t->flags & TF_ONE_WAY)) {
...
} else {
...
}
//将BINDER_WORK_TRANSACTION添加到目标队列,本次通信的目标队列为target_thread->todo
t->work.type = BINDER_WORK_TRANSACTION;
list_add_tail(&t->work.entry, target_list);
//将BINDER_WORK_TRANSACTION_COMPLETE添加到当前线程的todo队列
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
//唤醒等待队列,本次通信的目标队列为target_thread->wait
if (target_wait)
wake_up_interruptible(target_wait);
return;
binder_transaction -> binder_thread_read -> IPC.waitForResponse,收到BR_REPLY来回收buffer.
5.3 BR_REPLY
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
int32_t cmd;
int32_t err;
while (1) {
if ((err=talkWithDriver()) < NO_ERROR) break; // 【见小节2.11】
if (mIn.dataAvail() == 0) continue;
...
cmd = mIn.readInt32();
switch (cmd) {
...
case BR_REPLY:
{
binder_transaction_data tr;
err = mIn.read(&tr, sizeof(tr));
if (err != NO_ERROR) goto finish;
if (reply) {
...
} else {
// 释放buffer[见小节5.4]
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), this);
continue;
}
}
goto finish;
default:
err = executeCommand(cmd);
...
break;
}
}
...
}
5.4 IPC.freeBuffer
void IPCThreadState::freeBuffer(Parcel* parcel, const uint8_t* data,
size_t /*dataSize*/,
const binder_size_t* /*objects*/,
size_t /*objectsSize*/, void* /*cookie*/)
{
if (parcel != NULL) parcel->closeFileDescriptors();
IPCThreadState* state = self();
state->mOut.writeInt32(BC_FREE_BUFFER);
state->mOut.writePointer((uintptr_t)data);
}
将BC_FREE_BUFFER写入mOut,再talkWithDriver()
5.5 BC_FREE_BUFFER
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
//拷贝用户空间的cmd命令,此时为BC_FREE_BUFFER
if (get_user(cmd, (uint32_t __user *)ptr)) -EFAULT;
ptr += sizeof(uint32_t);
switch (cmd) {
case BC_TRANSACTION:
case BC_REPLY: ...
case BC_FREE_BUFFER: {
void __user *data_ptr;
struct binder_buffer *buffer;
if (get_user(data_ptr, (void * __user *)ptr)) return -EFAULT;
ptr += sizeof(void *);
buffer = binder_buffer_lookup(proc, data_ptr);
...
if (buffer->transaction) {
buffer->transaction->buffer = NULL;
buffer->transaction = NULL;
}
// binder_buffer存在异步事务,且binder_node不为空
if (buffer->async_transaction && buffer->target_node) {
if (list_empty(&buffer->target_node->async_todo))
buffer->target_node->has_async_transaction = 0;
else
//当异步队列async_todo也不为空,则事务追加到该线程todo队列.
list_move_tail(buffer->target_node->async_todo.next, &thread->todo);
}
binder_transaction_buffer_release(proc, buffer, NULL);
binder_free_buf(proc, buffer);
break;
}
}
*consumed = ptr - buffer;
}
return 0;
}
接收端线程处理BC_FREE_BUFFER命令:
- 当binder_buffer存在异步事务,当异步队列async_todo也不为空,则事务追加到该线程todo队列.
- 释放当前的buffer.
5.6 binder_thread_read
binder_thread_read(){
...
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
//从线程todo队列获取事务数据
if (!list_empty(&thread->todo)) {
w = list_first_entry(&thread->todo, struct binder_work, entry);
} else if (!list_empty(&proc->todo) && wait_for_proc_work) {
...
} else {
...
}
switch (w->type) {
case BINDER_WORK_TRANSACTION:
//获取transaction数据
t = container_of(w, struct binder_transaction, work);
break;
...
}
...
if (t->buffer->target_node) {
//获取目标node
struct binder_node *target_node = t->buffer->target_node;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
t->saved_priority = task_nice(current);
...
cmd = BR_TRANSACTION; //设置命令为BR_TRANSACTION
} else {
tr.target.ptr = NULL;
tr.cookie = NULL;
cmd = BR_REPLY; //设置命令为BR_REPLY
}
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = t->sender_euid;
...
//将cmd和数据写回用户空间
if (put_user(cmd, (uint32_t __user *)ptr)) return -EFAULT;
ptr += sizeof(uint32_t);
if (copy_to_user(ptr, &tr, sizeof(tr))) return -EFAULT;
ptr += sizeof(tr);
list_del(&t->work.entry);
t->buffer->allow_user_free = 1;
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;
} else {
t->buffer->transaction = NULL;
kfree(t); //通信完成,则运行释放
}
break;
}
...
return 0;
}
六. 总结
本文详细地介绍如何从AMP.startService是如何通过Binder一步步调用进入到system_server进程的AMS.startService. 整个过程涉及Java framework, native, kernel driver各个层面知识. 仅仅一个Binder IPC调用, 就花费了如此大篇幅来讲解, 可见系统之庞大. 整个过程的调用流程:
6.1 通信流程
从通信流程角度来看整个过程:
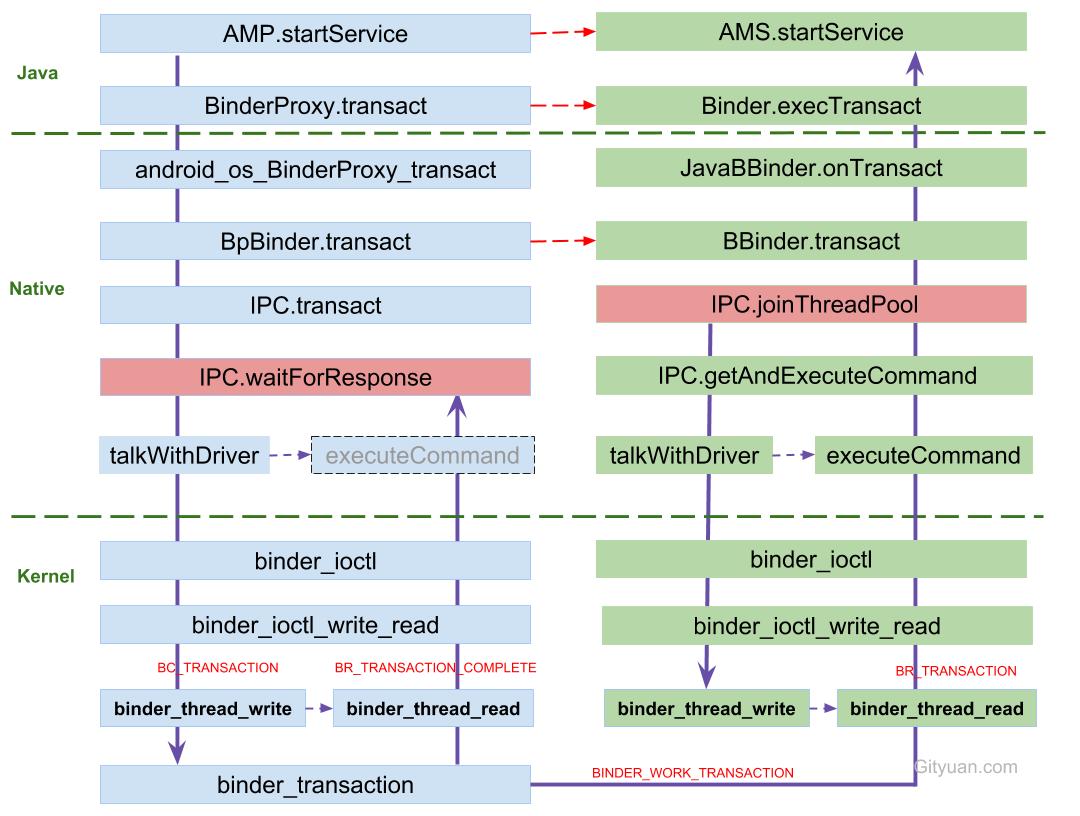
图解:
- 发起端线程向Binder Driver发起binder ioctl请求后, 便采用环不断talkWithDriver,此时该线程处于阻塞状态, 直到收到如下BR_XXX命令才会结束该过程.
- BR_TRANSACTION_COMPLETE: oneway模式下,收到该命令则退出
- BR_REPLY: 非oneway模式下,收到该命令才退出;
- BR_DEAD_REPLY: 目标进程/线程/binder实体为空, 以及释放正在等待reply的binder thread或者binder buffer;
- BR_FAILED_REPLY: 情况较多,比如非法handle, 错误事务栈, security, 内存不足, buffer不足, 数据拷贝失败, 节点创建失败, 各种不匹配等问题
- BR_ACQUIRE_RESULT: 目前未使用的协议;
- 左图中waitForResponse收到BR_TRANSACTION_COMPLETE,则直接退出循环, 则没有机会执行executeCommand()方法, 故将其颜色画为灰色. 除以上5种BR_XXX命令, 当收到其他BR命令,则都会执行executeCommand过程.
- 目标Binder线程创建后, 便进入joinThreadPool()方法, 采用循环不断地循环执行getAndExecuteCommand()方法, 当bwr的读写buffer都没有数据时,则阻塞在binder_thread_read的wait_event过程. 另外,正常情况下binder线程一旦创建则不会退出.
6.2 通信协议
从通信协议的角度来看这个过程:
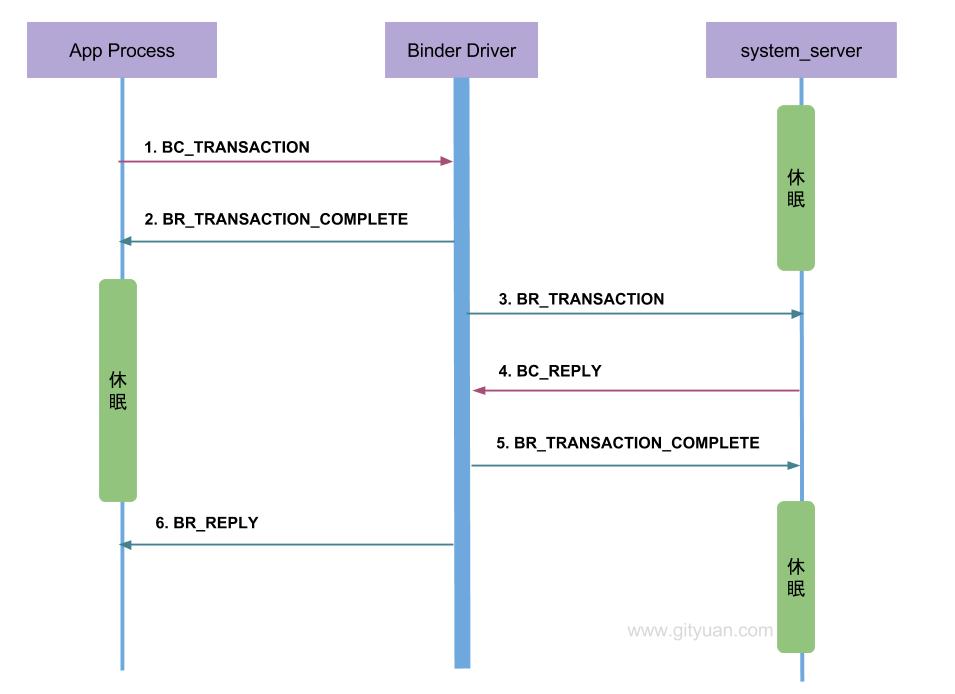
- Binder客户端或者服务端向Binder Driver发送的命令都是以BC_开头,例如本文的
BC_TRANSACTION和BC_REPLY, 所有Binder Driver向Binder客户端或者服务端发送的命令则都是以BR_开头, 例如本文中的BR_TRANSACTION和BR_REPLY. - 只有当
BC_TRANSACTION或者BC_REPLY时, 才调用binder_transaction()来处理事务. 并且都会回应调用者一个BINDER_WORK_TRANSACTION_COMPLETE事务, 经过binder_thread_read()会转变成BR_TRANSACTION_COMPLETE. - startService过程便是一个非oneway的过程, 那么oneway的通信过程如下所述.
6.3 说一说oneway
上图是非oneway通信过程的协议图, 下图则是对于oneway场景下的通信协议图:
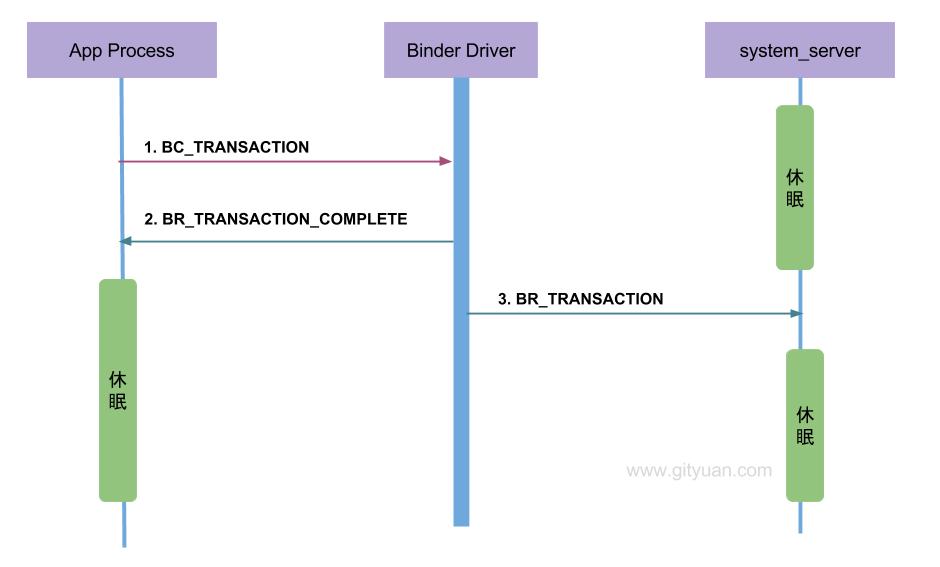
当收到BR_TRANSACTION_COMPLETE则程序返回,有人可能觉得好奇,为何oneway怎么还要等待回应消息? 我举个例子,你就明白了.
你(app进程)要给远方的家人(system_server进程)邮寄一封信(transaction), 你需要通过邮寄员(Binder Driver)来完成.整个过程如下:
- 你把信交给邮寄员(
BC_TRANSACTION); - 邮寄员收到信后, 填一张单子给你作为一份回执(
BR_TRANSACTION_COMPLETE). 这样你才放心知道邮递员已确定接收信, 否则就这样走了,信到底有没有交到邮递员手里都不知道,这样的通信实在太让人不省心, 长时间收不到远方家人的回信, 无法得知是在路的中途信件丢失呢,还是压根就没有交到邮递员的手里. 所以说oneway也得知道信是投递状态是否成功. - 邮递员利用交通工具(Binder Driver),将信交给了你的家人(
BR_TRANSACTION);
当你收到回执(BR_TRANSACTION_COMPLETE)时心里也不期待家人回信, 那么这便是一次oneway的通信过程.
如果你希望家人回信, 那便是非oneway的过程,在上述步骤2后并不是直接返回,而是继续等待着收到家人的回信, 经历前3个步骤之后继续执行:
- 家人收到信后, 立马写了个回信交给邮递员
BC_REPLY; - 同样,邮递员要写一个回执(
BR_TRANSACTION_COMPLETE)给你家人; - 邮递员再次利用交通工具(Binder Driver), 将回信成功交到你的手上(
BR_REPLY)
这便是一次完成的非oneway通信过程.
oneway与非oneway: 都是需要等待Binder Driver的回应消息BR_TRANSACTION_COMPLETE. 主要区别在于oneway的通信收到BR_TRANSACTION_COMPLETE则返回,而不会再等待BR_REPLY消息的到来. 另外,oneway的binder IPC则接收端无法获取对方的pid.
6.4 小规律
- BC_TRANSACTION + BC_REPLY = BR_TRANSACTION_COMPLETE + BR_DEAD_REPLY + BR_FAILED_REPLY
- Binder线程只有当本线程的thread->todo队列为空,并且thread->transaction_stack也为空,才会去处理当前进程的事务, 否则会继续处理或等待当前线程的todo队列事务。换句话说,就是只有当前线程的事务;
- binder_thread_write: 添加成员到todo队列;
- binder_thread_read: 消耗todo队列;
- 对于处于空闲可用的,或者Ready的binder线程是指停在binder_thread_read()的wait_event地方的Binder线程;
- 每一次BR_TRANSACTION或者BR_REPLY结束之后都会调用freeBuffer().
- ProcessState.mHandleToObject记录着handle与对应的BpBinder信息。
整个过程copy once便是指binder_transaction()过程把binder_transaction_data->data拷贝到目标进程的buffer。
6.5 数据流
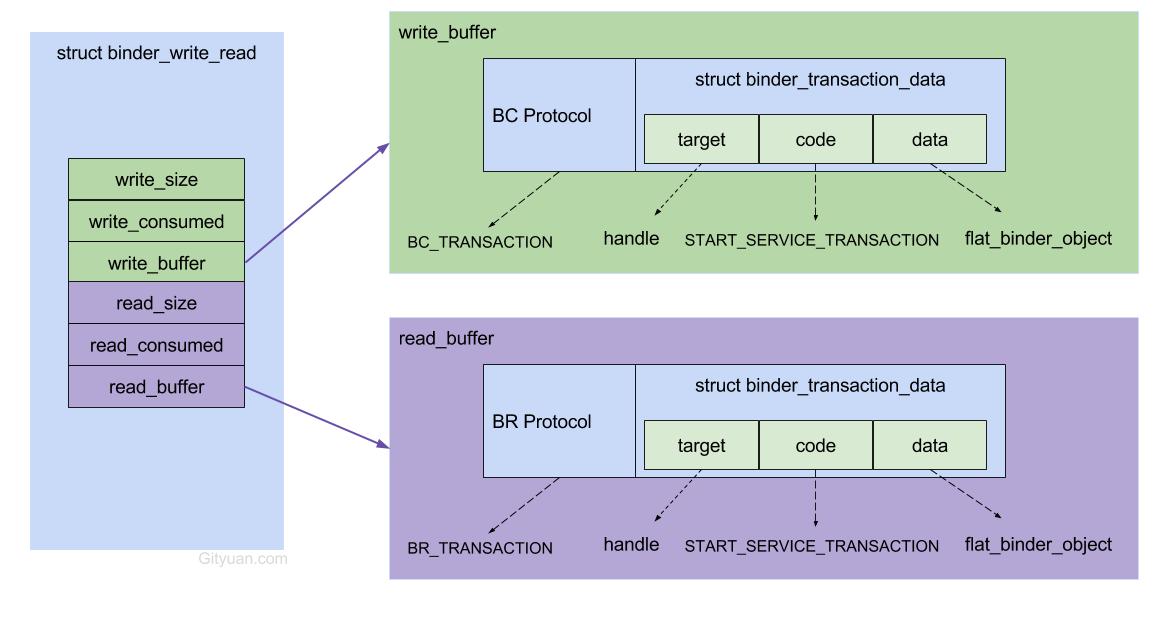
- [2.1]AMP.startService:组装flat_binder_object对象等组成的Parcel data;
- [2.9]IPC.writeTransactionData:组装BC_TRANSACTION和binder_transaction_data结构体,写入mOut;
- [2.11]IPC.talkWithDriver: 组装BINDER_WRITE_READ和binder_write_read结构体,通过ioctl传输到驱动层。
进入驱动后
- [3.3]binder_thread_write: 处理binder_write_read.write_buffer数据
- [3.4]binder_transaction: 处理write_buffer.binder_transaction_data数据;
- 创建binder_transaction结构体,记录事务通信的线程来源以及事务链条等相关信息;
- 分配binder_buffer结构体,拷贝当前线程binder_transaction_data的data数据到binder_buffer->data;
- [3.5]binder_thread_read: 处理binder_transaction结构体数据
- 组装cmd=BR_TRANSACTION和binder_transaction_data结构体,写入binder_write_read.read_buffer数据
回到用户空间
- [4.3]IPC.executeCommand:处理BR_TRANSACTION命令, 将binder_transaction_data数据解析成BBinder.transact()所需的参数
- [4.7] AMN.onTransact: 层层回调,进入该方法,反序列化数据后,调用startService()方法。
微信公众号 Gityuan | 微博 weibo.com/gityuan | 博客 留言区交流